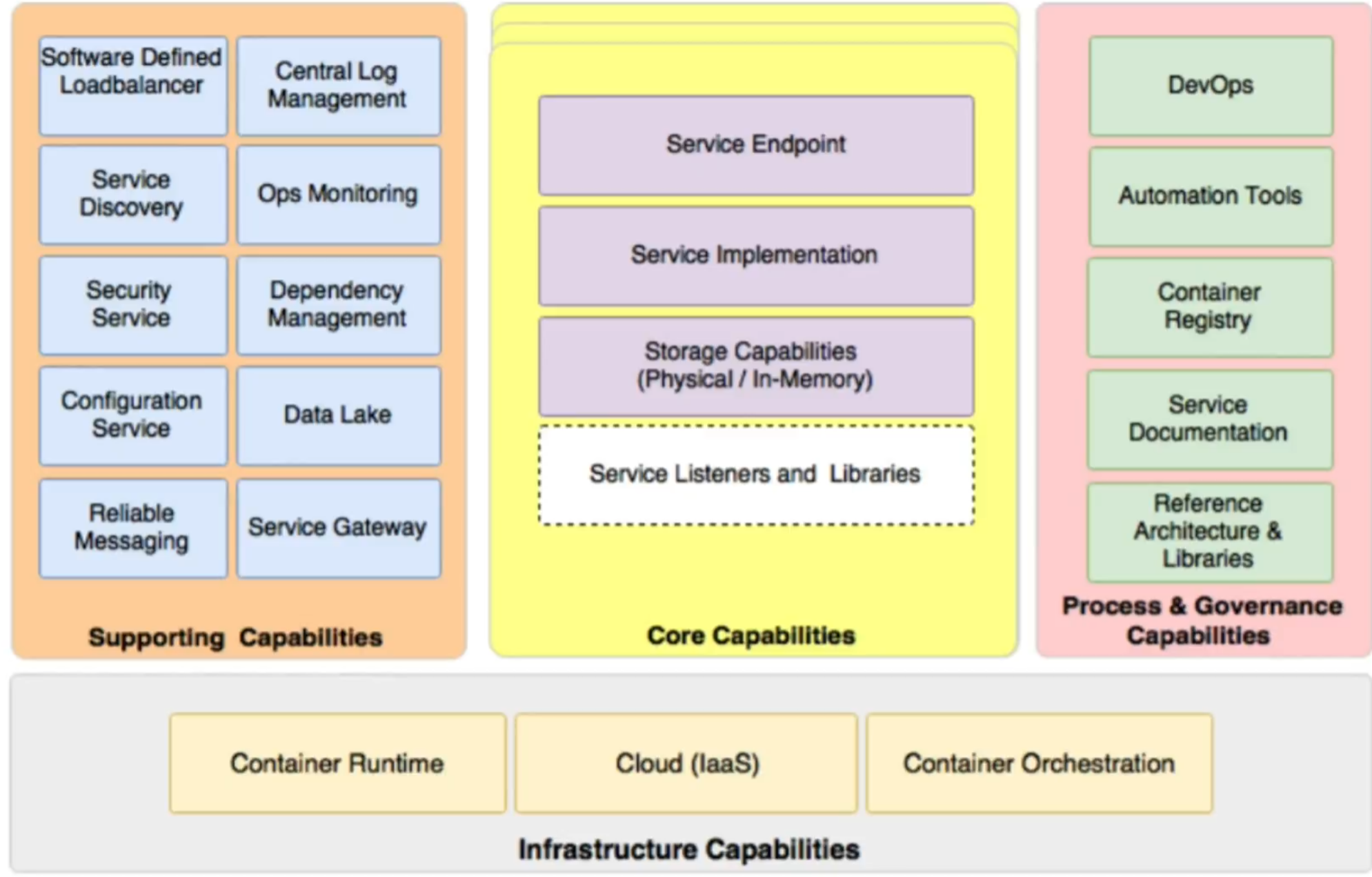
마이크로서비스를 도입하는데 앞서 아래 4가지 capabailties이 내재되어 있어야함
Core capabilities- 서비스 별 배포 되는 SW 패키지에 필수 요소
Supporting capabilities - 지원 기술 및 설계 패턴
Infrastructure capabilities - 컨테이너 및 컨테이너 오케스트레이션
Process & Governanace capabilities - DevOps 및 문서화
Core capabilities
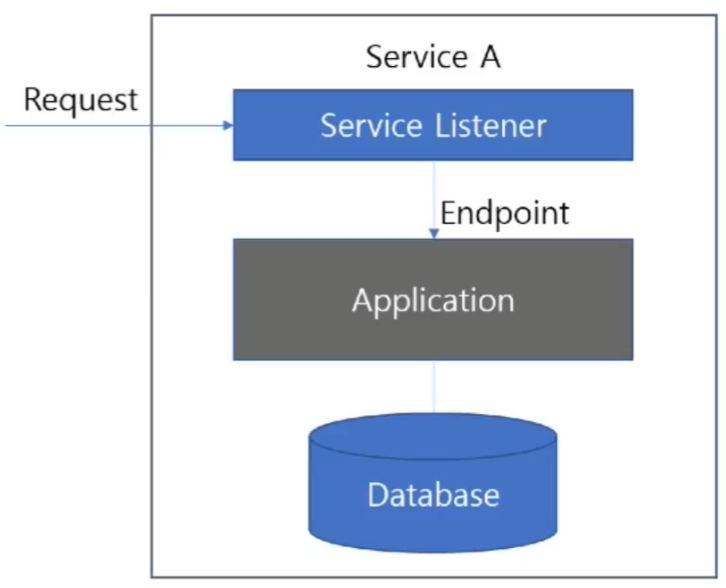
Core capabilities은 단일 서비스 내에 패키징 되는 SW 컴포넌트들(구현체) 이다.
- 서비스 Listener : 외부로부터 request 받았을 때 Endpoint로 전달하는 역할
- Endpoint : 받은 request를 SW 컴포넌트로 전달하는 역
- Application : 서비스 구현체
- 데이터 저장 : 단일 서비스의 데이터를 담고 있는 저장소
서비스 Listener
- HTTP 등의 Listener 가 애플리케이션에 내장되어 있어야함
- 새로운 서비스를 개발 했을 때 배포를 쉽게 하기 위함
- 일례 : Web Server, Web Application Server, Spring Boot 같은 Self Contained 방식
- tomcat 등의 WAS가 설치 되어 있고 앱을 WAS에 배포하는 형식은 하면 안됨, 새로운 서비스에 대한 배포가 힘듬
Endpoint
- HTTP 요청을 받아 처리 할 API가 애플리케이션 내부에 있어야함
- 다양한 프로토콜 사용 가능
Application
- 서비스 로직의 구현체
- 로직은 단일 책임의 원칙을 지켜야 함 (1기능만 수행)
- 응집도 높게 구현, 계층형 아키텍처를 사용하는 것이 좋음
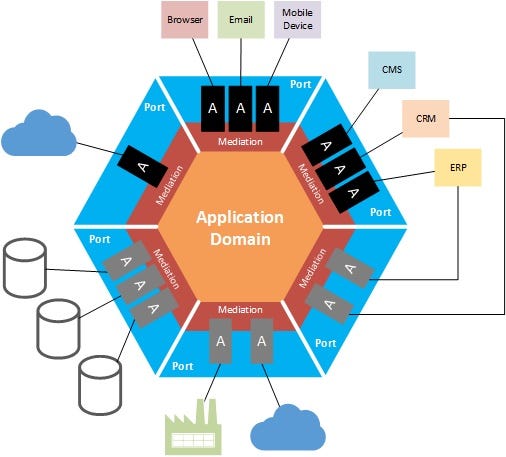
- Hexagonal architecture를 만족해야함
- 외부 기술과 분리시켜야함
- 일례 1 DB를 무엇을 쓰던 비즈니스 핵심 로직은 변경이 필요 없어야함
- 일례 2 Queue를 무엇을 쓰던 비즈니스 핵심 로직은 변경이 필요 없어야함
- 일례 3 모바일/웹 등 UI에 따라서도 비즈니스 핵심 로직은 변경이 필요 없어야함
데이터 저장
- 각 서비스 마다 데이터를 저장할 데이터 소스가 있어야 함
- 데이터소스는 하나의 서비스에 한정 되야 함
- 각각의 서비스는 데이터에 대해 독립적 이어야
Infrastructure capabilities
Infrastructure capabilities 아래 3가지의 역량이 필요함
- 클라우드
- 컨테이너 런타임
- 컨테이너 오케스트레이션
클라우드
- On Demand
- 대용량 확장 가능한 환경
- 몇 번의 클릭만으로 리소스 사용 가능해야함
- Auto Scaling으로 자동화 된 Provisioning
- 다양한 자원/서비스 제공
- 컴퓨팅 자원, DB, NoSQL, Big Data, AI
컨테이너 런타임
- 각 서비스들이 다양한 기술 사용
- 수백/수천 개의 인스턴스에 배포 해야함
- 컨테이너 기술을 이용하여 빠른 환경 구성 및 배포 필요
- 컨테이너 이미지에는 런타임과 코드가 동시에 존재
- Docker
컨테이너 오케스트레이션
- 많은 수의 컨테이너의 관리 역량 필요
- 배포, 모니터링 등 운영 관리 비용을 최소화 하기 위함
- Kebernetes
Supporting capabilities
- Service Discovery
- Config Server
- API Gateway
- SW Defined Load Balancer
- Circuit Breaker
- Distributed Tracing
- Data Lake
- Messaging
Service Discovery
- 서비스 개수 및 인스턴스 개수가 급증함으로 전체 Topology가 복잡해
- 한 서비스에서 다른 서비스를 호출 할 때 필요한 정보를 유지하는 것이 복잡해짐 (Service IP, Port 등..)
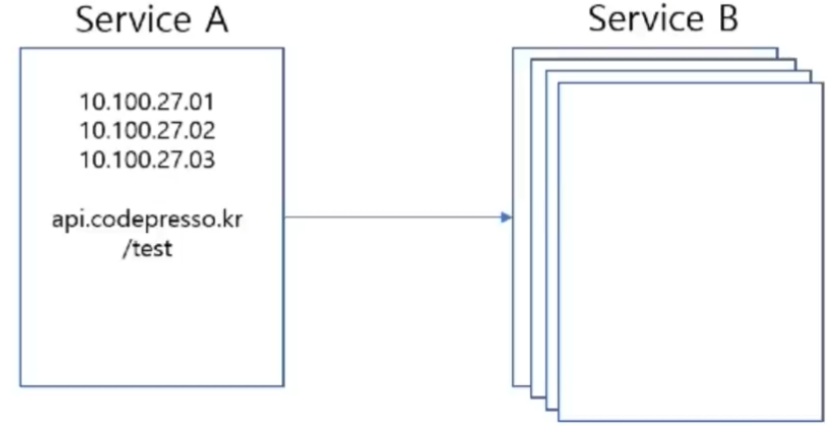
- 중앙에서 시스템의 모든 서비스에 대한 정보를 저장
- 새로운 인스턴스가 생성되면 중앙 시스템에게 자신의 정보를 등록
- 서비스 간에는 다른 서비스의 정보를 유지해야 하는 기능을 제거
- DNS 서버를 이용 하듯이 서비스를 호출할 인스턴스는 호출할 서비스의 이름(getAccount 등..)을 이용해 호출
- 중앙 시스템은 인스턴스 및 서비스를 추가 삭제 가능해야함

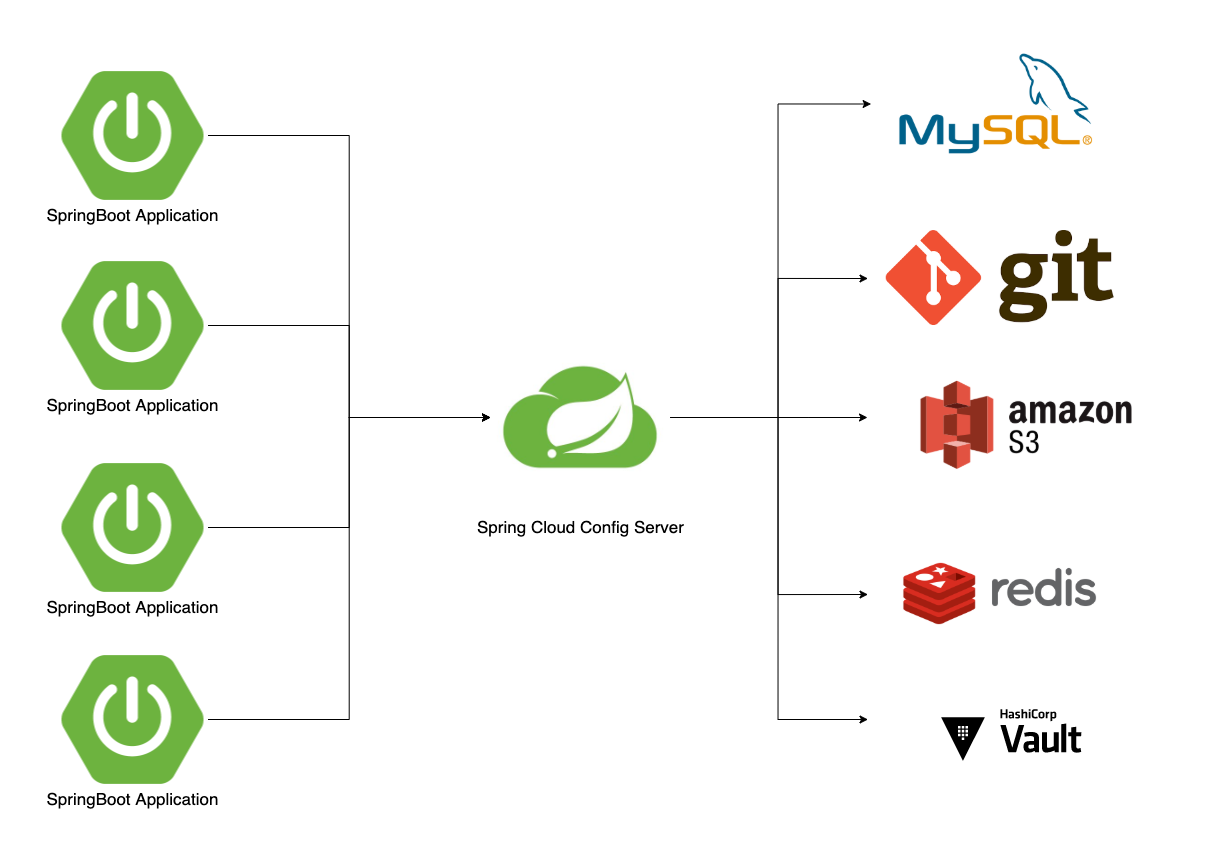
Config Server
- MSA를 도입하면 서비스가 많아 지면서 Config 파일, OS 설정 파일들의 갯수가 급증함
- Service 구동 환경마다 새롭게 빌드/패키징을 해야하게 됨
- 중앙 Config Server에서 설정 관리, 저장 Backend는 Git, DBMS를 사용함
- 서비스들은 Application Runtime 중에 중앙 Config Server를 통해 정보를 획득
- 설정 정보가 변경된다면 중앙 Config Server의 설정 파일을 툴을 이용해 변경
Service Gateway
- 다양한 서비스들에 대한 단일 진입 점을 제공
- 인증, 인가, 로깅, 필터링 등의 공통 처리 수행
- 서비스에 문제 발생 시 요청을 차단하거나 대안 경로로 변경하는 기능 수행

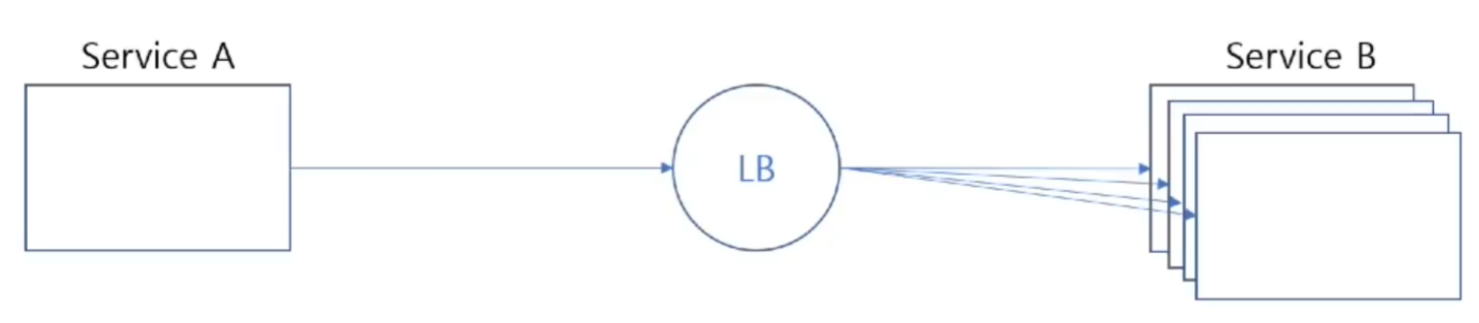
SW Defined Load Balancer
- 서비스를 호출하는 클라이언트에서 SW로 Load Balancing 수행

Circuit Breaker
- 서비스 장애 시 장애 전파를 막기 위함
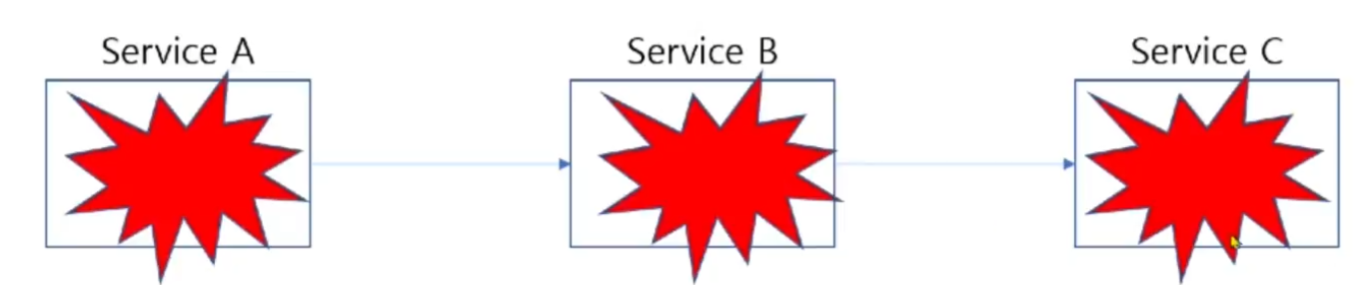
- 특정 Servivce의 장애는 그 Service만의 장애로 격리시키는 것이 중요함
- Service 간의 Circuit Breaker 컴포넌트 도입
- Service에게 요청했을 때 해당 요청은 Circuit Breaker를 통해 요청
- Circuit Breaker를 연결되어있는 Service를 모니터링하여 문제 발생이 예측되는 경우 차단 시킴
- Circuit Breaker에 의해 차단된 Service는 정상화 작업 수행 (문제 분석 -> 코드 수정 -> 빌드 -> 테스트 -> 배포)

Distributed Tracing
- 서비스 간 모든 호출에 추적 ID를 삽입 (ID 예시 : 암호화한 문자열, 암호화한 정보)
- 추적 ID를 Key로 하여 단일 API 트랜잭션 활동을 파악

Data Lake
- 비정형 raw 데이터를 그대로 저장( Hadoop, HDFS이용)
- 데이터 분석 시점에 데이터 가공
- 전통적인 ETL이 아닌 실시간 Data Ingestion 도구 사용 (Flume, Kafka, Logstash...)
Messaging
- Messaging 기반 이벤트 주도 설계는 서비스 간 결합도를 낮춤
- 고가용성의 Messaging 솔루션 필
- RabbitMQ, ActiveMQ, Kafka, AWS Kinesis
Process & Governanace capabilities
- DevOps
- 자동화 도구
- 컨테이너 레지스트리
- 문서화
- 참조 아키텍처 및 라이브러리
DevOps
- 애자일과 DevOps는 필수임 (조직에 맞는 방법론을 선택 후 실행)
- 한팀에서 지속적 통합, 배포, 운영, 모니터링이 되어야함
- 애자일을 도입하여 짧은 개발 주기로 반복하여 빠른 업데이트 및 배포 (자동화!!!)
- 통합, 배포, QA 모두 자동화!!
자동화 도구
- 다수의 서비스를 테스트, 배포, 운영 가능 하도록 하는 자동화 도구를 갖춰야함
- 테스트, 배포, 모니터링 경보 자동화
컨테리어 레지스트리
- MSA에서 컨테이너는 필수임
- 코드 형상 관리와 같이 이미지도 형상 관리를 해야함
- Docker Hub, GCR, ECR ...
문서화
- 서비스들은 인터페이스를 기준으로 통신함
- 인터페이스 문서화!!
- 인터페이스 문서는 아래 정보를 내포함
- 필수/선택 파라미터
- 버전
- 응답 정보
- 에러 코드
- 인터페이스 정보는 웹으로 쉽게 열람할 수 있어야 함
- Spring REST Docs, Swagger ...
참조 아키텍처 및 라이브러리
- 탈중앙화 된 방식은 비효율성을 야기 할 수 있음
- 서로 다른 아키텍처로 인한 유지 보수성 악화
- 동일한 기능의 재개발
- 조직의 기술 별 참조 모델, 아키텍처는 중요
- 참조 아키텍처는 사내 프레임워크화 할 수도 있음 -> 전사 개발 팀들은 프레임워크를 기반으로 Service를 개발
- 중족 개발을 막기위해 사내 오픈소스 라이브러리 활동
- 사내 인프라에서 기능 검색
- 사내 프레임워크 개발 활동에 대한 보상
'Program > Software Architect' 카테고리의 다른 글
| [마이크로서비스 5] 도커 컨테이너 (0) | 2024.08.22 |
|---|---|
| [마이크로서비스 4] 마이크로 서비스 성숙도 평가 모델 (0) | 2024.08.18 |
| [마이크로서비스 2] 마이크로 서비스 장/단점 (0) | 2024.08.12 |
| [마이크로서비스 1] 마이크로 서비스 개요 (0) | 2024.08.11 |
| 실용주의 프로그래머 Topic 51 실용주의 시작 도구 (0) | 2024.07.25 |