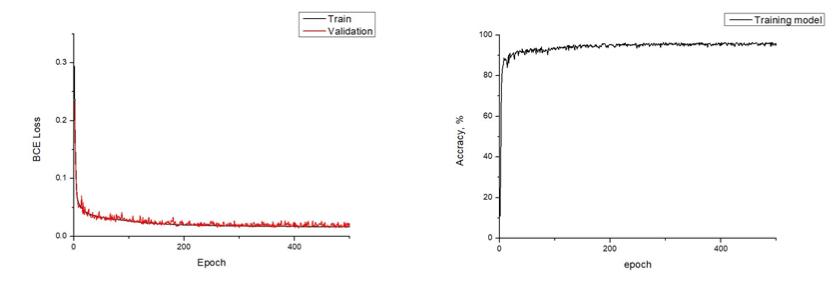
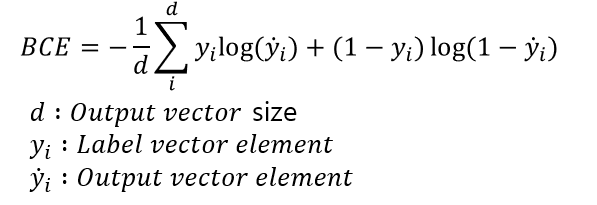본 포스팅은 아래 선행 작업들이 있다.
- OpenCV 4.2 가 설치되 있고, 아래 명령어를 사용 가능한 상태여야한다.
- opencv_createsamples
- opencv_traincascade
- 학습 데이터가 수집 되어 있는 상태이다.
진행 순서
1. opencv_createsamples 실행 파일을 이용해 학습 데이터 생성하기 (out : .vec 파일)
2. opencv_traincascade 실행 파일을 이용해 검출기 생성하기 (out : .xml 파일)
3. .xml 파일을 이용해 객체 검출 해보기
1. opencv_createsamples 실행 파일을 이용해 학습 데이터 생성하기
파라미터 설명
opencv_createsamples -info <description_file_name> -vec <vec_file_name><description_file_name> : 검출을 원하는 이미지 데이터들이 기록되어있는 텍스트 file 이름 (positive 샘플이라한다.)
<vec> : 생성된 학습 데이터를 저장할 파일명 (확장자 : vec)
<background_file_name> : 검출할 이미지가 없는 이미지들이 기록되어있는 텍스트 file 이름 (negative 샘플이라한다.)
명령어 입력 예시
opencv_createsamples -info positive_list.txt -vec tr.vec -bg negative_list.txt
positive_list.txt 파일 구성은 아래와 같이 구성해야한다.
c:\positives\img1.jpg 1 140 100 45 45
c:\positives\img2.jpg 2 100 20 50 50 0 30 25 25
c:\positives\img3.jpg 1 0 0 20 20
....첫번째 인자 : 이미지 파일 경로
두번째 인자 : 이미지에 구성되어있는 positive 샘플의 갯수
세번째 인자 : x, y, width, height
positive 샘플의 갯수가 2개 이상이면 세번째 인자를 주르륵 이어서 쓰면됨
2. opencv_traincascade 실행 파일을 이용해 학습 모델 생성하기
opencv_traincascade -data <cascade_dir_name> -vec <vec_file_name> -bg <background_file_name> [-numStages <number_of_stages = 20>] [-featureType <HAAR(default), LBP, HOG] [-baseFormatSave]파라미터 설명
<cascade_dir_name> : 최종 검출기가 저장될 파일 이름 (최종 출력 확장자 .xml)
(일례 '-data result' 로 실행 시 result라는 폴더가 생성되고 result 밑에 cascade classifier들이 저장됨. 또한 현재 실행폴더에 result.xml이라는 이름으로 학습된 최종 검출기가 저장됨.)
<vec_file_name> : 앞서 생성 했던 학습 데이터 파일명 (확장자 : vec)
<background_file_name> : 검출할 이미지가 없는 이미지들이 기록되어있는 텍스트 file 이름 (negative 샘플이라한다.)
[<HARR, LBP, HOG> (default : HARR)] : 검출 모드 설정(옵션)
[<number_of_stages> (default : 20)] : 학습할 cascade 단계의 수. Cascade 검출기는 일련의 기본 검출기들로 구성되는데, Cascade 검출 방식은 먼저 1단계 classifier로 false들을 걸러내고, 나머지에 대해서는 2단계 classifier로 false들을 걸러내고, ... 이런식으로 해서 최종 단계까지 살아남으면 물체 검출에 성공한 것으로 간주함. -nstages는 이 단계수 즉, 기본 검출기들의 개수를 조절하는 것임. 학습된 각 단계별 기본 검출기들은 result\ 밑에 0, 1, 2, ... 밑에 텍스트 파일 형태로 저장됨. (옵션)
[-baseFormatSave (default : false)] : -featureType이 HAAR일 경우에만 의미를 가지는 파라미터임. 이 파라미터를 명시해 주면 훈련 결과를 예전의 Haar training 방식의 데이터 포맷으로 저장해줌. (옵션)
명령어 입력 예시
opencv_traincascade -data result -vec tr.vec -bg negative_list.txt -numPos 400 -numNeg 5000 -featureType HAAR -numState 14 -baseFormatSave
negative_list.txt 파일 구성은 아래와 같이 구성해야한다.
c:\negatives\img1.jpg
c:\negatives\img2.jpg첫번째 인자 : 이미지 파일 경로
-npos: 각 cascade 학습 단계(stage)에 사용되는 positive 샘플 개수를 설정. 주의할 점은 .vec 파일에 있는 실제 샘플수를 입력하면 안됨. npos <= (vec파일에 있는 샘플수 - 100)/(1+(nstages-1)*(1-minhitrate))) 정도로 값을 주기 바람.
-nneg: 각 cascade 학습 단계(stage)에 사용될 negative 샘플 개수를 설정. -bg로 입력한 negative 이미지들 중에서 다양한 위치 및 크기로 negative 샘플들을 뽑기 때문에 실제 negative 이미지 개수와 관계없이 원하는 값을 주면 됨.
-minhitrate: 각 cascade 단계의 기본 classifier들에게 요구되는 최소 검출율. 최종 검출기의 검출율은 minhitrate^nstages가 됨. 예를 들어, 기본값을 그대로 사용하면 최소 0.995^14 = 0.932 정도의 검출율을 가지는 detector를 얻을 수 있게 됨. 하지만 이것은 어디까지나 .vec 파일로 입력한 training 데이터에 대한 검출율이기 때문에 실제 일반적인 입력에 대한 검출율은 훨씬 떨어질 수 있음.
3. .xml 파일을 이용해 객체 검출 해보기
#include "opencv2/objdetect.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/videoio.hpp"
#include <iostream>
#include <string>
using namespace std;
using namespace cv;
void detectAndDisplay(const CascadeClassifier& classfier, Mat frame )
{
Mat frame_gray;
cvtColor( frame, frame_gray, COLOR_BGR2GRAY );
//-- Detect objects
std::vector<Rect> objects;
classfier.detectMultiScale( frame_gray, objects );
for ( size_t i = 0; i < objects.size(); i++ )
{
Point center( objects[i].x + objects[i].width/2, objects[i].y + objects[i].height/2 );
ellipse( frame, center, Size( objects[i].width/2, objects[i].height/2 ), 0, 0, 360, Scalar( 255, 0, 255 ), 4 );
}
//-- Show what you got
imshow( "Capture - object detection", frame );
}
int main(void)
{
CascadeClassifier classfier;
//-- 1. Load the cascades
string cascade_name = "trained.xml";
if( !classfier.load( cascade_name ) )
{
cout << "--(!)Error loading face cascade\n";
return -1;
};
Mat frame;
... 이미지 읽기
//-- 2. Apply the classifier to the frame
detectAndDisplay(classfier,frame);
}
참고 사이트 :
https://darkpgmr.tistory.com/70
OpenCV Haar/cascade training 튜토리얼
OpenCV의 Haar classifier, Cascade classifier를 학습시키기 위한 샘플 데이터 생성법 및 training 방법에 대한 상세 메뉴얼입니다. Haar training이나 cascade training에 대한 내용은 OpenCV 웹 매뉴얼이나 Naotoshi Seo의
darkpgmr.tistory.com
https://docs.opencv.org/3.4/db/d28/tutorial_cascade_classifier.html
OpenCV: Cascade Classifier
Next Tutorial: Cascade Classifier Training Goal In this tutorial, We will learn how the Haar cascade object detection works. We will see the basics of face detection and eye detection using the Haar Feature-based Cascade Classifiers We will use the cv::Cas
docs.opencv.org
'M.S > Machine learning' 카테고리의 다른 글
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM RBF kernel) (0) | 2023.07.12 |
|---|---|
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM) (0) | 2023.07.10 |
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(Perceptron) (0) | 2023.07.09 |
| Q-Learning 기반 스케줄링 (0) | 2021.05.18 |
| (DNN) 8명 중 1등, 2등 고르기 (0) | 2021.03.22 |