목표
1. (Support Vector Machine; SVM)을 이해하고 꽃 분류 모델을 만든다.
2. 학습한 SVM에 대해 Decision boundry 그래프를 그려본다.
1. (Support Vector Machine; SVM) 을 이해하고 꽃 분류 모델을 만든다.
SVM 이란?
- SVM을 이해하려면 Decision boundry, 서포트 벡터, 마진을 알아야한다.
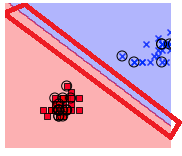
1. decision boundry
- 직역하면 결정 경계선을 의미한다.
2. support vector
- 결정 경계선에서 가장 가까운 데이터를 의미한다. 가깝다는 것은 간단하게 L2 Norm으로 계산했을 때 나오는 값을 봤을 때 다른 데이터 보다 작은 값을 의미한다.
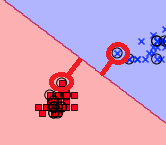
3. margin
- 서포트 벡터와 결정 경계선간의 거리
- 마진을 최대화했다 -> 일반화 오차를 낮췄다.
- 마진을 최소화했다 -> 일반화 오차가 크다. (오버피팅)
- SVM은 학습을 통해 서로 다른 레이블과 매칭하는 특성 데이터의 support vector와 생성할 decision boudry 간에 margin값을 최대화하는 것이 목표이다.
- soft margin classification : 이전의 SVM에서 슬랙 변수를 이용하여 선형적으로 구분되지 않는 데이터에서 선형 제약 조건을 완화시킨 분류기이다.
from sklearn.svm import SVC
svm = SVC(kernel='linear', C=1.0, random_state=1)
svm.fit(X_train_std, y_train)- 위는 SVM을 생성하고 학습시키는 코드이다.
- SVC인 이유는 Support Vector classification 이기 때문이다. (SVM과 학습 원리 동일)
- 이때 C 값은 마진 폭을 조절해 주는 변수이다. C 값을 조절하여 편향-분산 트레이드오프 (bais vs variance trade-off)를 조절한다.
2. 학습한 SVM에 대해 Decision boundry 그래프를 그려본다.
plot_decision_regions(X_combined_std, y_combined,classifier=svm, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()- 위 코드는 학습한 모델을 아래 챕터에서 정의한 함수를 재사용하여 그리는 코드이다.
https://computervision-is-fun.tistory.com/111
- 아래 그림은 학습한 SVM의 Decision boundry 그래프이다.
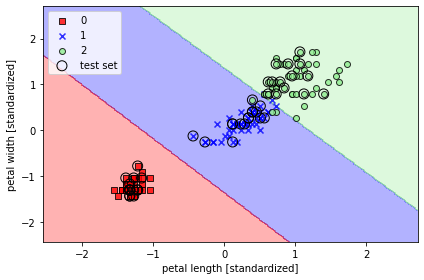
끝
'M.S > Machine learning' 카테고리의 다른 글
| OpenCV 4.2, Harr cascade 기반 원하는 객체 검출 과정 (0) | 2023.08.22 |
|---|---|
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM RBF kernel) (0) | 2023.07.12 |
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(Perceptron) (0) | 2023.07.09 |
| Q-Learning 기반 스케줄링 (0) | 2021.05.18 |
| (DNN) 8명 중 1등, 2등 고르기 (0) | 2021.03.22 |