TrainData <X, Y>
Traindata set X
| 영수 | 철수 | 영희 | 도희 | 찰스 | 백희 | 가희 | 슈렉 |
| 32 | 54 | -12 | 53 | 254 | 13 | 98 | 41 |
Traindata set Y
1등
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
2등
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
DNN Model (Logistic Regression)
- Node 구성
| InputLayer Node | HiddenLayer Node | OutputLayer Node |
| 8 | 16x32x64x32 | 16 |
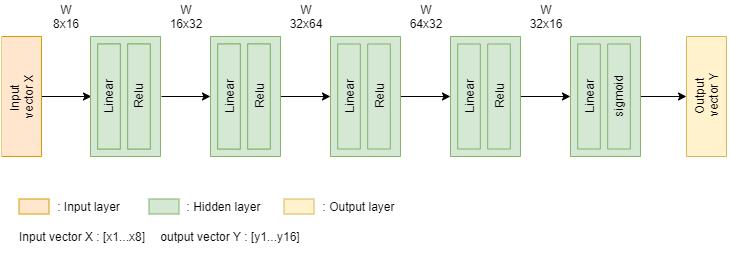
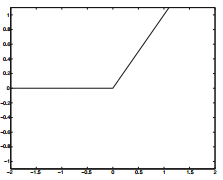
- Hidden Layer Activate Function
ReLU
- Output Layer Activate Function
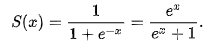
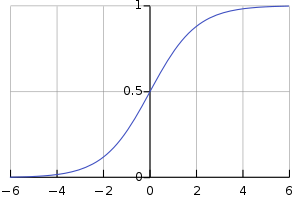
설명 : sigmoid를 통해 output의 결과값을 0~1사이의 값,
즉 확률로 표현한다.
ex 0.0 -> 0%
0.5 -> 50%
1.0 -> 100%
- Loss Function
BCE(Binary Cross Entropy Error)
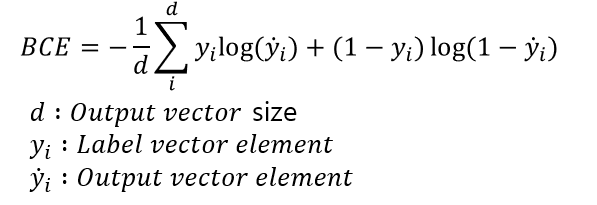
설명 : BCE function은 0~1사이의 결과값을 모두 고려한 Loss를 뽑을 수 있다.
따라서 OutputLayer에는 sigmoid function 또는 softmax function 등 Output vector값이
정규화되어 있어야 한다. 물론 Pytorch에서는 Sigmoid function + BCE loss function
을 제공하는 Function이 있으며,
나는 설계한 아웃풋 레이어에서 이미 Sigmoid가 포함되어있기 때문에 BCE function만 썼다.
- Optimization Method
SGD(Stochastic Gradient Descent)
Code
- DNN Model
#Neual Netrok nn.Module 상속
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = nn.Linear(8,16)
self.l2 = nn.Linear(16,32)
self.l3 = nn.Linear(32,64)
self.l4 = nn.Linear(64,32)
self.l5 = nn.Linear(32,16)
def forward(self, x):
x = x.float()
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
h3 = F.relu(self.l3(h2))
h4 = F.relu(self.l4(h3))
h5 = F.sigmoid(self.l5(h4))
return h5
- Train function
#학습 함수
def train(epochcount, train_loader, validation_loader, aryofLoss, nShowInterval):
running_loss = 0.0
#traind_loader로 부터 데이터를 랜덤으로 가져온다.
for i, data in enumerate(train_loader):
#i : trn_loader index, data : set <inputs, labes>
inputs, labels = data
#모델 훈련 모드로 전환
model.train(True)
#최적화 함수 초기화
optimizer.zero_grad()
#모델 유추 시작
output = model(inputs)
#추론 결과 손실 값 취득
#오차 output, labels
test_loss = criterion(output, labels.float())
#오차 역전파
test_loss.backward()
optimizer.step()
#오차 값 표기
lossValue = test_loss.item()
running_loss += lossValue
#nShowInterval번 순회시 누적 train loss 상태 보여주고, Validation 체크 하기
if i % nShowInterval == (nShowInterval - 1): # print every 2000 mini-batches
aryoftempLoss = []
print('[%d, %5d] loss: %.3f' %(epochcount + 1, i + 1, running_loss / nShowInterval))
aryoftempLoss.append(running_loss/nShowInterval)
aryofLoss.append(artoftempLoss)
running_loss = 0.0
validationRunning_loss= 0.0
#validation 체크 구간
for valindex, valdata in enumerate(validation_loader):
validationinputs, validationlabels = valdata
#모델 테스트 모드로 전환
model.train(False)
validationoutput = model(validationinputs)
#오차 output, labels
validationloss = criterion(validationoutput, validationlabels.float())
validationlossValue = validationloss.item()
validationRunning_loss += validationlossValue
#validation loss 저장
validationTempLoss = []
validationSize = len(validation_loader)
validationRunning_loss /= validationSize
validationTempLoss.append(validationRunning_loss)
aryofValidationLoss.append(validationTempLoss)
print('Validationloss: %.3f' %(validationRunning_loss)) - Test function
#테스트 함수
def test(log_interval, model, test_loader, aryofModelInfo):
#모델 테스트 모드로 전환
model.eval()
#Test loss 수집용
test_loss = 0
#correct rate 수집용
correct = 0
with torch.no_grad():
for data, target in test_loader:
#추론 시작
output = model(data)
#오차 output, labels
test_loss += criterion(output, target.float())
target1 = target[0][0:8]
target2 = target[0][8:16]
output1 = output[0][0:8]
output2 = output[0][8:16]
#추론 결과 직접 비교
if torch.max(target1,0)[1] == torch.max(output1,0)[1] and torch.max(target2,0)[1] == torch.max(output2,0)[1]:
correct += 1
#추론 결과 평균 수집
test_loss /= len(test_loader.dataset)
#추론 결과 보여줌
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format
(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
aryOfTempInfo = []
aryOfTempInfo.append(test_loss.item())
aryOfTempInfo.append(correct)
aryOfTempInfo.append(100. * correct / len(test_loader.dataset))
aryofModelInfo.append(artOfTempInfo)
- Save Model
modelPath = "./model"
createFolder(modelPath)
MakeCSVFile(modelPath, "ModelLossInfo.csv", ["Loss"], aryofLoss)
MakeCSVFile(modelPath, "ModelValidationLossInfo.csv", ["Validation Loss"], aryofValidationLoss)
MakeCSVFile(modelPath, "ModelSpec.csv",["Average Loss","Correct","Accracy"],aryofModelInfo)
torch.save(model, modelPath + '/model.pt')
Simulation
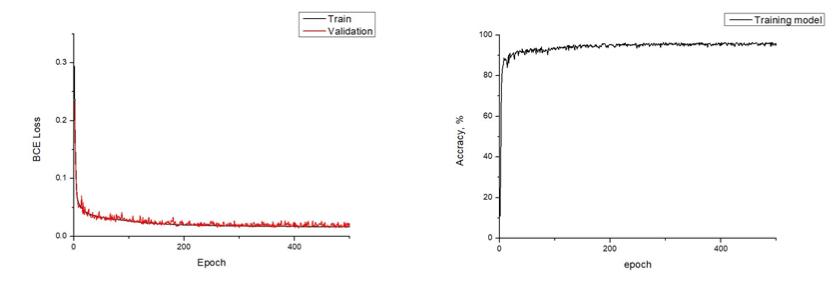
개인적인 의견
두 번째로 모델링 한 DNN Model이다. 간단한 1등 찾기 모델은 쉽게 구현했으나, Classification 분야에서 Multi Classification 분야로 활용하는 부분을 구현하기 위해 Output layer의 활성화 함수 그리고 Loss function을 선정하는 부분이 제일 힘들었다. Loss function은 10분쯤 생각해봐야 하는 공식이다. 어찌 보면 당연한 공식이지만 왜 당연한지 생각해 봐야 한다. 그리고 생각보다 걱정했던 오버 피팅 문제는 없었다. 왜 없었을까..? 서적에서 참고 했을때는 모델의 복잡도와 데이터의 수의 관계에 따라 오버피팅 문제가 생길 수 있다고 했는데 흠.. 아직 이런 부분은 센스가 부족한 것 같다.
추가로 공부해야 할 부분 : Chain rule, Backpropagation, Bias & Variance, Optimization issue
'M.S > Machine learning' 카테고리의 다른 글
| OpenCV 4.2, Harr cascade 기반 원하는 객체 검출 과정 (0) | 2023.08.22 |
|---|---|
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM RBF kernel) (0) | 2023.07.12 |
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM) (0) | 2023.07.10 |
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(Perceptron) (0) | 2023.07.09 |
| Q-Learning 기반 스케줄링 (0) | 2021.05.18 |