시스템 설계
STATE
자료구조 : Dictionary
key : snr1, snr2, snr3, snr4 -> 정수형 으로 변환후 저장.
value : Action value function (2개씩 고르는 모든 경우의 수를 가짐)
이유 :
Dictionary쓰는 이유 4개의 vector를 좀 더 단순하게 다루기 위해 문자열로 변환 후 저장 하면 그 값 자체가 고유의 key를 의미 하기 때문. (ex: key : '10,2,3,-1', value : [10,2,0,2,1,3] ).
REWARD
첫번째 시도 -> 특정 값에 수렴하지만 최적의 값은 아니 었음.
Reward : 차분값을 이용한 방법
(select SNR 적용 후 처리율 - 이전 처리율) + (선택)(select SNR 적용 후 fairness - 이전 fairness)
두번째 시도 -> 기존의 MR Scheduling과 동일한 성능.
Reward : 해당 상태에서 뽑아냈던 최대 처리율과 현재 선택한 snr의 최대 처리율의 차분값을 이용
선택한 SNR이 이전에 선택했던 최대 처리율 보다 높으면 positive 값 적용
선택한 SNR이 이전에 선택했던 최대 처리율 보다 낮으면 negative 값 적용
(select SNR 적용 후 처리율 - 이전 최대 처리율) + (선택)(select SNR 적용 후 fairness - 이전 fairness)
이유 : 목적이 처리율이므로. 선택적으로 fairness를 고려할 수도 있음.
ACTION
epsilon-greedy (1 iteration : epsilon /= 1.5)
P(epsilon) -> greedy
P(1-epsilon) -> random
이유 : 잘못된 초기화 값을 대비하여 구성
UPDATE
Q(s,a) = Q(s,a) + alpha * (Reward + gamma * argmax(Q(s',a)) - Q(s,a))
Q-Learning 기반 ->
빠른 convergence 결과를 볼 수 있음 + 상대적으로 많이 쓰임.
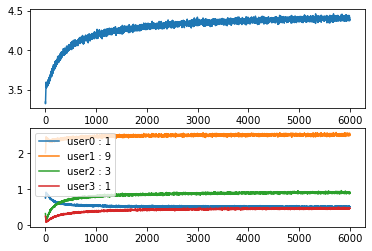
학습 및 시뮬레이션 그래프
'M.S > Machine learning' 카테고리의 다른 글
| OpenCV 4.2, Harr cascade 기반 원하는 객체 검출 과정 (0) | 2023.08.22 |
|---|---|
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM RBF kernel) (0) | 2023.07.12 |
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(SVM) (0) | 2023.07.10 |
| sklearn을 이용한 꽃 분류 모델 만들고 시각화 하기(Perceptron) (0) | 2023.07.09 |
| (DNN) 8명 중 1등, 2등 고르기 (0) | 2021.03.22 |