박싱
값 타입(Value Type)이나 참조 타입(Reference Type)을 System.Object로 변환하는 작업.
언박싱
박싱한 System.Object 타입을 박싱 이전의 타입으로 변환하는 작업.
그중 오늘은 값 타입의 박싱 연산, 언박싱 연산에 대해 포스팅을 하겠다.
값 타입과 참조 타입에 대해서는 이전 포스팅을 참고하길 바란다.
computervision-is-fun.tistory.com/21
값 타입, 참조 타입
1. 값 타입 (struct, enum) - new 예약어를 통해 할당시킨 값 타입은 스레드 스택 메모리에 저장되므로, 스레드가 종료될 시 스택의 순서대로 삭제 된다. (GC의 오버헤드가 없다) - = 연산시 필드 값
computervision-is-fun.tistory.com
값 타입의 박싱
값 타입은 생성 시 스레드의 스택 메모리에 저장되고, 참조 값이 아닌 값 자체를 다룬다.
참조 타입과 여러모로 대조가 된다.
이런 설명을 전재로 아래와 같이 값 타입을 ArrayList에 저장시키면 어떤 동작이 일어나까??
struct Point
{
int nPtX;
int nPtY;
public Point(int nInputPtX, int nInputPtY)
{
nPtX = nInputPtX;
nPtY = nInputPtY;
}
}
public static void Main()
{
Point pt = new Point(1,2);
ArrayList arrList = new ArrayList();
arrList.Add(pt);
}ArrayList의 Add함수를 살펴보자
public virtual Int32 Add(Object Value);이처럼 Add함수는 Object를 매개변수로 동작한다.
그리고 위 코드는 참조 타입 매개변수에 값 타입을 넣어도 동작이 되었다.
왜 그럴까??
이유는 값 형식의 Point를 참조 형식의 Object로 박싱 명령을 내부적으로 진행했기 때문이다.
박싱은 내부적으로 어떤 동작을 할까??
어떻게 스레드 스택 메모리에 저장되어있는 데이터가 관리되는 힙 메모리에 저장되는 것일까?
순서는 이렇다.
1. 관리되는 힙 메모리에 Point의 필드 멤버를 고려하여 메모리가 할당된다. 이때 참조 형식이므로 타입 객체 포인터와 동기화 블록 인덱스라는 필드를 포함하여 할당한다.
2. 값 타입인 Point의 필드 멤버 변수들을 관리되는 힙 메모리에 복사시킨다.
3. 새로 생성된 참조 타입의 Point의 포인터를 반환한다.
이제 실제 위의 동작을 하는지 ILDASM.EME(역어 셈)으로 실행해보겠다.
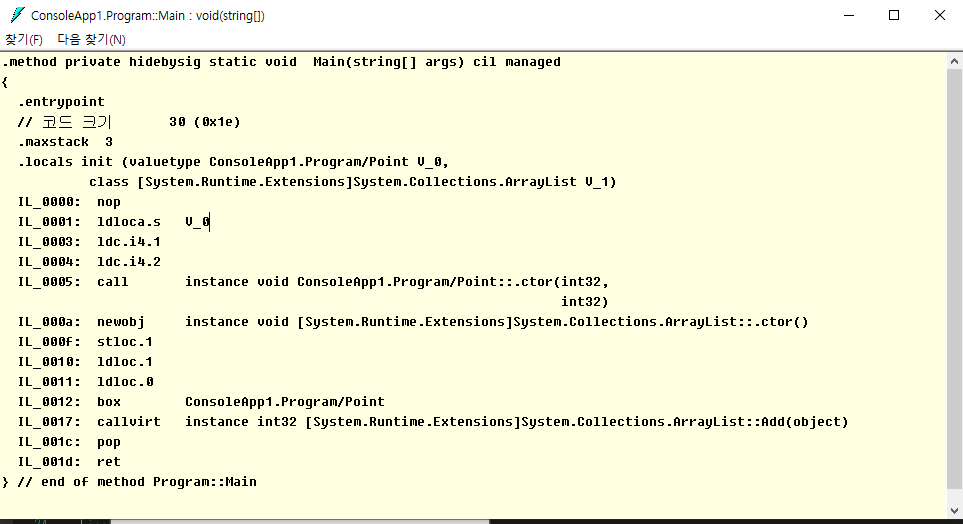
아쉽게도 더욱 자세한 코드는 보기 힘들 것 같다. 하지만 위와 같이 box라는 부수적인 명령어가 붙으면서 우리는 박싱 동작을 짐작할 수 있다. 박싱 동작을 더욱 자세히 확인할 수 있는 방법은 더 찾아봐야겠다.
추가로 박싱 된 참조 타입의 Point는 기존의 값 타입의 Point보다 생명주기가 길다.
이유는 관리되는 힙 메모리가 저장되었기 때문에 다음 GC의 호출을 기다리기 때문이다.
값 타입의 언박싱
Object에 저장되어있던 참조 형식의 Point가 값 형식의 Point로 변환하는 작업을 말한다.
CLR은 언박싱을 수행하면 아래와 같은 동작을 한다.
1. 관리되는 힙 메모리에서 참조 형식의 Point의 필드 값들의 주소를 가져온다.
(ex nPtX, nPtY)
2. 이 값들은 스레드 스택 메모리의 Point에 복사시킨다.
위의 과정과 아래의 코드를 역어 셈으로 보겠다.
static void Main(string[] args)
{
Point pt = new Point(1, 2);
Object o = pt;
pt = (Point)o;
}

IL_0012 명령 줄을 보면 unbox라 하고 Object를 Point의 값 타입으로 복사시킨 것을 알 수 있다.
결론
값 타입의 박싱과 언박싱 모두 의도하지 않게 복사 동작을 진행한다. 따라서 우리는 값 타입의 박싱과 언박싱을 최소화해야 한다.
'Program > C#' 카테고리의 다른 글
| const 상수 (1) | 2020.12.20 |
|---|---|
| 값 타입, 참조 타입 (0) | 2020.12.13 |
| 네임스페이스와 어셈블리 (1) | 2020.12.05 |
| 타입에 대하여2 (0) | 2020.12.02 |
| 타입에 대하여1 (1) | 2020.11.29 |