Health&Program
2024. 8. 24. 21:49
2024. 8. 24. 21:49
MSA를 구축하고 호스트 서버, 컨테이너를 관리할 때에는 아래의 기능이 필요
- 대량의 컨테이너를 쉽게/자동으로 관리하기 위해 사용
- 다수의 호스트(서버)를 하나의 클러스터처럼 사용
- 여러 개의 호스트(서버)에 컨테이너 배포
- 서비스 디스커버리로 서비스들을 연결
- 부하가 생기면 서버를 자동으로 Scale-out
- 장애가 발생하면 기존 컨테이너 kill 후 새로운 컨테이너 다시 생성
- 컨테이너 Health Check
- 컨테이너 간 Storage 및 Network 관리
Kubernetes

- 컨테이너 오케스트레이션 도구
- 분산 환경에서 대규모의 컨테이너 관리
- 이외 Docker Swarm, Apache Mesos/Marathon 등 도구들이 있음
- Kubernetes가 그중 거의 표준처럼 사용
- 멀티 호스트에서 컨테이너 관리
- 컨테이너 배포
- 컨테이너 간 네트워크 관리
- 컨테이너 모니터링
- 컨테이너 업데이트
- 장애 발생 시 자동 복구
Kubernetes 철학
- 철학 1 : Immutable Infrastructure
- 클라우드 환경에서 자원들을 간단하게 구축하고 파기 가능
- 한번 구축한 인프라는 수정하지 않음
- 원하는 상태를 만들어서 새로운 환경을 구축
- 현재 운영되고 있는 인프라의 상태를 관리
- 서버의 Java version은 올려야 하는 경우 업데이트한 Java version을 담고있는 컨테이너를 배포
- 철학 2 : Declarative Configuration
- 명령형이 아닌 선언형
- 구구절절 노노 -> 정해진 것 하나 shell 스크립트 하나 실행 시키듯.
- 원하는 상태를 만들기 위해 명령어를 하나 씩 치는 방식이 아님
- 원하는 상태를 기술하여 Kubernetes에 적용
- 원하는 상태 = 시스템이 되어 있어야 할 모습
- 앱을 클러스터 안에서 몇 개 올릴지
- 네트워크 구성은 어떻게 되어야 할지
- Desired State
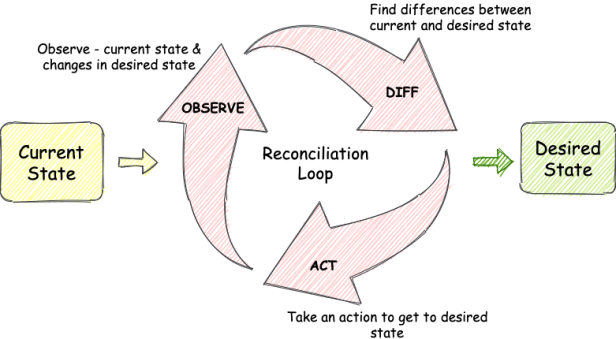
어떤 컨테이너들이 어떤 노드 위에서 동작 할지
- 컨테이너들이 replica set이 몇 개가 되어야하는지 등..
- 관리자가 최종적으로 바라는 상태
- 현재 상태를 실시간 모니터링
- 관리자가 설정한 원하는 새로운 상태를 주문하거나 클러스터의 상태가 변경되면 Kubernetes가 원하는 상태로 조정
- 철학 3 : Self Healing
- 장애 발생 시 자동으로 복구
- 사람의 개입을 최소화 함
- 시스템이 되어 있어야 하는 상태를 항상 감시
- 원하는 상태와 다를 경우에 자동으로 복구
Docker Swarm

- 설치와 사용이 Kubernetes에 비해 단순
- 단 대용량 분산환경에서 사용하기에는 기능이 부족
- 모니터링 기능 부재
- 스토리지 옵션 기능 부재
Apache Mesos/Marathon

- 분산 시스템 커널
- 분산 된 CPU, memory, storage 등을 추상화 하여 하나의 단일 리소스처럼 만듦
- Marathon은 컨테이너 관리 도구
- Mesos와 Marathon의 통합으로 대규모 환경의 컨테이너들을 관리할 수 있음