목표
- Double Deep Q Network가 Deep Q Network의 어떤 문제를 어떻게 해결했는지 이해한다.
- Double Deep Q Network의 동작 방식을 이해하고 코드를 다룰 줄 안다.
DDQN의 특징
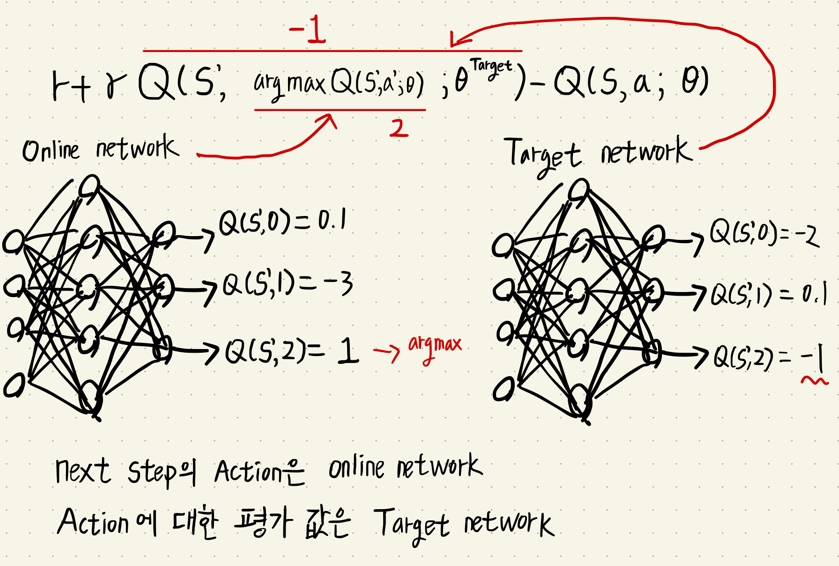
- Target network가 Online network의 행동을 평가한다.(max Q(s',a) 값을 평가한다)
- Double Q learning 은 2개의 Q table을 가지고 서로를 평가했지만 DNN 구조가 들어간 DDQN은 이미 target network, online network로 구분되어 있으므로 서로를 평가하는 방법으로 진행한다.
- 핵심은 행동( argmax(Q(s)))과 행동에 대한 평가( Q(s,argmax(Q(s)) ) 값을 분리했다는 것이다.
def optimize_model(self, experiences):
state, actions, reward, next_states, is_terminals = experiences
batch_size = len(is_terminals)
#online model에서 action index 취득
argmax_a_q_sp = self.online_model(next_states).max(1)[1]
q_sp = self.target_model(next_states).detach()
#online model에서 취득한 action index를 target model에서 뽑은 Q(s', action index) 로 값을 평가.
max_a_q_sp = q_sp[np.arange(batch_size), argmax_a_q_sp].unsqeeze(1)
target_q_sa = rewards + (self.gamma * max_a_q_sp * (1 - is_terminals))
q_sa = self.online_model(states).gather(1, actions)
td_error = q_sa - target_q_sa
value_loss = td_error.pow(2).mul(0.5).mean()
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optimizer.step()
정리
- DDQN 기법을 통해 DQN의 overestimation 문제를 어느 정도 감소시켰다.
- 핵심은 행동( argmax(Q(s)))과 행동에 대한 평가( Q(s,argmax(Q(s)) ) 값을 분리 한 것이다.
'M.S > Reinforcement learning' 카테고리의 다른 글
| 가치 기반 심층 강화학습의 Sample Efficiency를 향상 시킨 Dueling DQN, PER (0) | 2022.08.20 |
|---|---|
| MSE Loss, MAE Loss, Huber Loss (0) | 2022.08.12 |
| Deep Q Network(DQN)-가치 기반 심층 강화학습의 기초 (0) | 2022.08.11 |
| NFQ (Neural Fitted Q-Iteration)를 이용한 Q - function 근사화 (0) | 2022.08.09 |
| 강화학습 Agent를 이용한 MC control, SARSA, Q-Learning (0) | 2022.08.05 |