목표
- Deep Q Network가 이전의 심층 강화학습의 어떤 문제를 어떻게 해결했는지 이해한다.
- Deep Q Network의 동작 방식을 이해하고 코드를 다룰 줄 안다.
- Deep Q Network의 한계점을 이해한다.
DQN trick 1 - Target Network
- 기존 NFQ의 문제점은 Neural Network 가 update 하면서 next state의 Q function값이 동시에 업데이트 하면서 결론적으로 불안정한 업데이트 Loss 값이 생긴다.
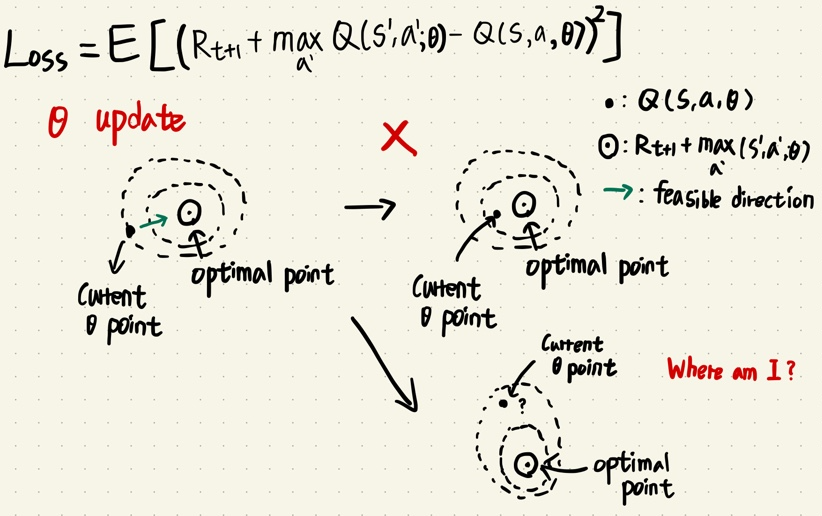
- 새롭게 제안한 Target network를 도입한 update 식

- 학습할때에는 target network는 k번의 학습 스탭마다 current network의 파라미터를 복사하고, k 번의 학습 스탭 동안 current network의 파라미터 값만 업데이트 하는 방법이다.
- 복잡한 환경일 수록 많은 학습 스탭이 필요하다. (아타리 게임 같이 CNN이 포함되어있는 모델은 10,000스텝 단위, 카트폴 환경 같이 직관적인 환경은 10~20 스텝 단위)
def optimize_model(self, experiences):
states, actions, rewards, next_states, is_terminals = experiences
batch_size = len(is_terminals)
#target model의 Q function 값을 이용
max_a_q_sp = self.target_model(next_states).detach().max(1)[0].unsqueeze(1)
target_q_sa = rewards + (self.gamma * max_a_q_sp * (1 - is_terminals))
#online model의 Q function 값을 이용
q_sa = self.online_model(states).gather(1, actions)
td_error = q_sa - target_q_sa
value_loss = td_error.pow(2).mul(0.5).mean()
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optmizer.step()
def update_network(self):
# 특정 학습 스텝이 지나면 online model의 파라미터를 target model의 파라미터로 복사함
for target, online in zip(self.target_model.parameters(), self.online_model.parameters()):
target.data.copy_(online.data)DQN trick 2 - Experience replay
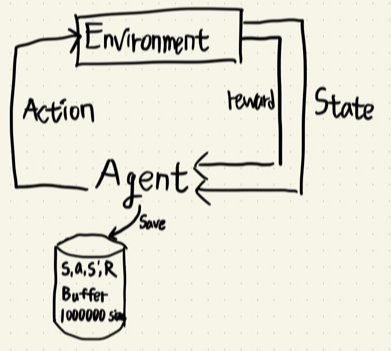
- 기존 NFQ에서 update에 사용한 데이터 셋은 IID 가정을 성립시키기 힘들었다.
- 업데이트 하는 미니배치 데이터셋은 모두 시간 관계성(순차적으로 들어오는 데이터)이 있었다.
- experience replay buffer 구조를 이용하여 IID 가정을 어느 정도 성립시키고, 데이터 튜플들간의 시간 관계성을 제거했다.
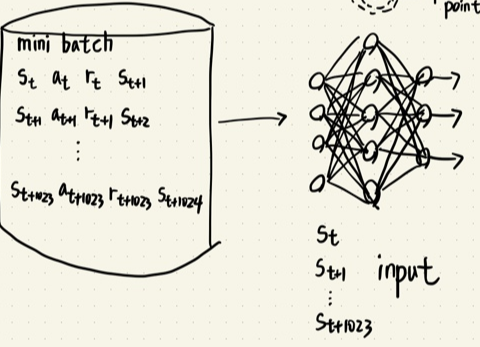
- 이 문제를 해결 하기위해 experience replay buffer 구조를 이용하여 state, action, reward, next state 튜플을 모두 저장하고 학습 Phase에서 experience replay buffer에서 mini batch 사이즈만큼 튜플을 샘플링하여 학습하는 방법을 사용했다.
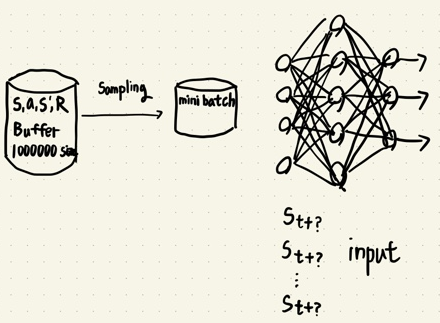
class ReplayBuffer():
def __init__(self,
max_size=50000,
batch_size=64):
self.ss_mem = np.empty(shape=(max_size), dtype=np.ndarray)
self.as_mem = np.empty(shape=(max_size), dtype=np.ndarray)
self.rs_mem = np.empty(shape=(max_size), dtype=np.ndarray)
self.nss_mem = np.empty(shape=(max_size), dtype=np.ndarray)
self.ds_mem = np.empty(shape=(max_size), dtype=np.ndarray)
self.max_size = max_size
self.batch_size = batch_size
self._idx = 0
self.size = 0
def store(self, sample):
s, a, r, ns, d = sample
self.ss_mem[self._idx] = s
self.as_mem[self._idx] = a
self.rs_mem[self._idx] = r
self.nss_mem[self._idx] = ns
self.ds_mem[self._idx] = d
self._idx += 1
self._idx = self._idx % self.max_size
self.size += 1
self.size = min(self.size, self.max_size)
def sample(self, batch_size=None):
if batch_size == None:
batch_size = self.batch_size
idxs = np.random.choice(self.size, batch_size, replace=False)
experiences = np.vstack(self.ss_mem[idxs]), np.vstack(self.as_mem[idxs]), \
np.vstack(self.rs_mem[idxs]), np.vstack(self.nss_mem[idxs]), \
np.vstack(self.ds_mem[idxs])
def __len__(self):
return self.sizeDNN의 parameter 사이즈에 따르는 팁
- State의 미세한 변화에 따라 다른 action을 해야하는 환경일 수록 DNN의 parameter의 수가 많을 수록 좋다. (너무 많으면 학습 시간이 오래걸리므로 그 중간 단계를 찾을 것)
DQN의 한계점
- 기존 Q-learning의 문제 중 Overestimation에 의한 maximization bias 문제를 가지고있다.
- Action space가 discrete 하게 쓰이므로 한계점이 있다. (DNN의 출력이 classfication 과 비슷한 역할을 함으로)
정리
- DQN은 기존 NFQ의 문제점을 해결하기 위해 2가지 트릭을 이용했다.
- 1. Experience replay : 경험을 매우큰 저장소에 저장하여 학습할때 샘플링하여 학습하는 방법
- 2. Target network : Target network를 고정시키고 Current network만 학습시키고 Current network가 지정한 학습 스탭수만큼 학습했다면 Target network에 복사시키는 방법.
- DQN은 최근 강화학습에서 매우 큰 영향을 끼친 방법이다. (DQN 논문 : Playing Atari with Deep Reinforcement Learning)
- 내 석사학위 논문도 DQN이 도와줬다 하하!!
'M.S > Reinforcement learning' 카테고리의 다른 글
| MSE Loss, MAE Loss, Huber Loss (0) | 2022.08.12 |
|---|---|
| DDQN(Double Deep Q Network) - DQN의 overestimation 극복 (0) | 2022.08.12 |
| NFQ (Neural Fitted Q-Iteration)를 이용한 Q - function 근사화 (0) | 2022.08.09 |
| 강화학습 Agent를 이용한 MC control, SARSA, Q-Learning (0) | 2022.08.05 |
| Model free 환경에서 사용하는 MC와 TD를 이용한 Value function prediction (0) | 2022.07.25 |