
소개

강화학습(Reinforcement Learning; RL)은 주어진 보상 함수를 통해 최적 정책을 계산한다.
역강화학습(Inverse Reinforcement Learing; IRL)은 최선의 행동 이력(최적 정책)을 입력으로 보상 함수를 찾는다.
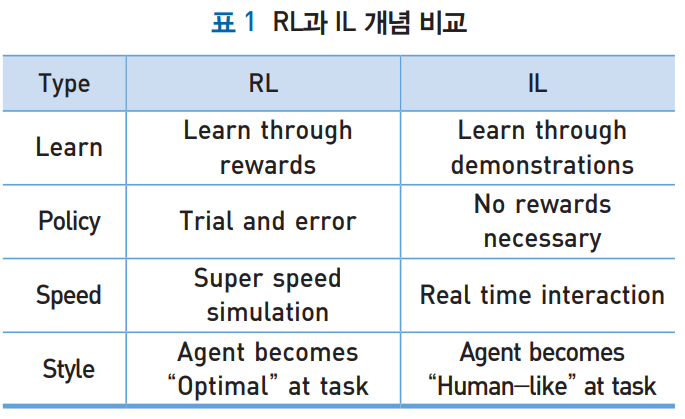
모방학습(Imitation Learning; IL)은 전문가의 행동을 모방하는 순차적 작업을 찾는다. 전문가가 최적 정책을 직접적으로 설계하여 전문가가 원하는 행동을 쉽게 발현 시키는데 장점이 있다.
모방학습
1. 행동복제(Behavior Cloning; BC)
- 전문가를 통해 쌍으로 이뤄진 (상태-행동) 쌍에 대한 시퀀스 궤적(Demonstration Trajectory)를 수집하여 정책을 지도학습한다.
- 지도학습 개념을 이용하기 때문에 복잡한 시퀀스 궤적을 학습시킬 때에는 많은 데이터가 필요하고, 테스트가 누적될수록 오차가 커지는 문제가 발생한다.
- 전문가에 의해 수동적으로 데이터를 수집하기 때문에 양적, 질적 한계가 존재하며, 누락된 데이터 쌍에 대해서는 성능이 현저하게 저하되는 문제가 발생한다.

2. 견습학습(Apprenticeship Learning, AL)
- 전문가를 통해 쌍으로 이뤄진 (상태-행동) 쌍에 대한 시퀀스 궤적(Demonstration Trajectory)을 수집하여 보상 함수를 만들고 계산된 보상함수를 통해 최적의 정책을 학습하는 알고리즘이다.
- IRL과 연계하면 BC에 비해 적은 데이터로 학습이 가능하고 예상치 못한 환경 대응에 강인하다.
- 전문가와 학습에이전트의 기대치집합으로 부터 계산된 성능 차이를 최소화하는 과정을 통해 보상값을 찾고, 이를 RL에 적용하여 최적 정책을 업데이트한다.
- 성능 차이가 임계치 이하로 수렴하면 학습을 종료한다.

3. IRL 알고리즘 종류
1. ALIRL
- TODO..
2. MaxEnt IRL
- TODO..
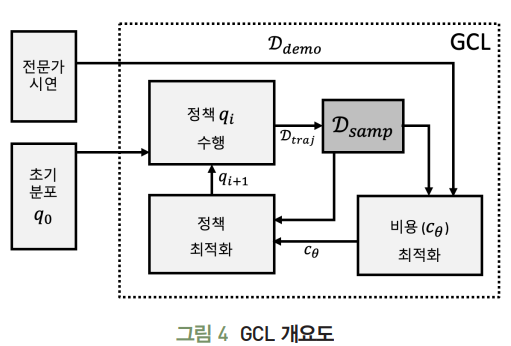
3. GCL
- TODO..
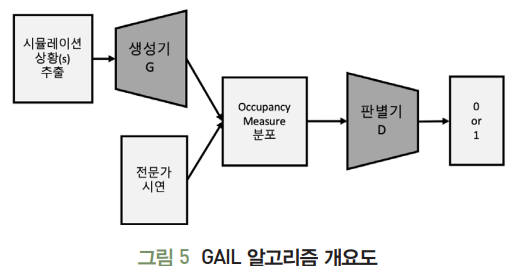
4. GAIL
- TODO..
5. VAIL
- TODO..

6. InfoGAIL
- TODO..
7. TD-GAIL(개인적으로 추가)
- 로봇에 적용한 논문 : Virtual Imitation Learning method based on TD3-GAIL for robot manipulator
- DOI : http://doi.org/10.5370/KIEE.2021.70.1.145
결론
- 최근 강화학습은 가상 시뮬레이션 환경의 연구 단계에서 자율 주행, 자연어 처리, 추천 시스템, 질병 진단 등 광범위한 응용 단계롤 확장되고 있음.
- 하지만 강화학습은 복잡한 실세계 환경에서 활용 가능성이 낮음. (더욱 많은 연구 필요)
- 역강화학습은 전문가의 시연 데이터를 통해 기존 강화학습 보다 좀 더 정확하고 세밀하게 목표 임무를 수행함.
- 특히 역강화학습은 인공 일반 지능(Artificial General Intelligence; AGI) 연구의 주요 핵심 기술이 될 것으로 기대됨.
DOI : 10.22648/ETRI.2019.J.340609
'M.S > Reinforcement learning' 카테고리의 다른 글
| 가치 기반 심층 강화학습의 Sample Efficiency를 향상 시킨 Dueling DQN, PER (0) | 2022.08.20 |
|---|---|
| MSE Loss, MAE Loss, Huber Loss (0) | 2022.08.12 |
| DDQN(Double Deep Q Network) - DQN의 overestimation 극복 (0) | 2022.08.12 |
| Deep Q Network(DQN)-가치 기반 심층 강화학습의 기초 (0) | 2022.08.11 |
| NFQ (Neural Fitted Q-Iteration)를 이용한 Q - function 근사화 (0) | 2022.08.09 |