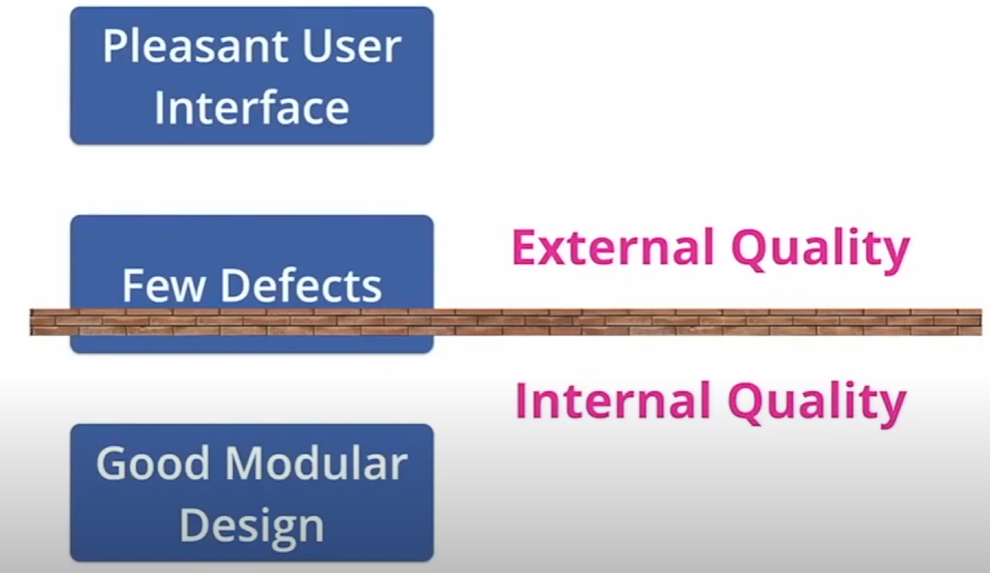
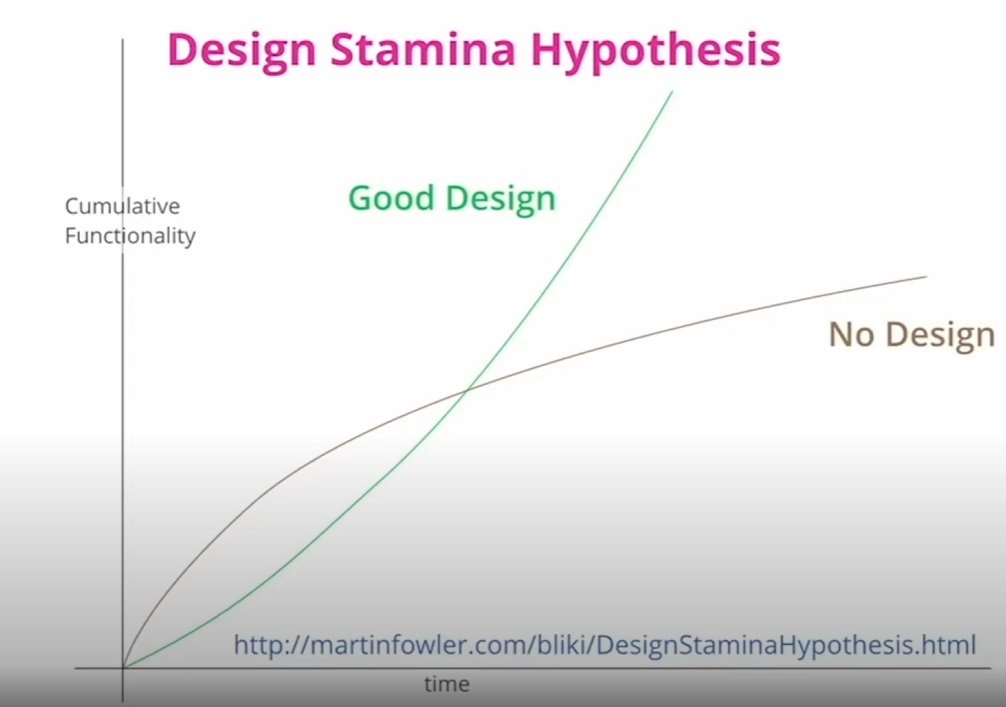
마이크로서비스란?
- 별도의 프로세스에서 실행
- HTTP API 같은 가벼운 매커니즘으로 통신하는 작은 애플리케이션
- 여러개의 분리되어있는 서비스들은 각자의 비즈니스 기능을 담당함
- 자동화 된 절차에 따라 서비스들은 독립적으로 배포됨
- 각 서비스는 서로 다른 프로그래밍 언어로 개발되어도 괜찮고, 서로 다른 데이터 저장소를 사용할 수 있음

마이크로서비스 관련 유명한 글 : https://martinfowler.com/articles/microservices.html
Microservices
Defining the microservices architectural style by describing their nine common characteristics
martinfowler.com
아마존의 모놀리틱시스템에서 마이크로서비스로 도입할 때 적용 규칙
- 모든 팀은 해당 팀의 기능 및 데이터를 Service Interface를 통해서만 노출 해야 한다.
- 다른 팀의 기능/데이터를 사용하려면 Network를 통한 Service Interface를 호출해야 한다.
- Service Interface 기술을 상관 하지 않겠다.(HTTP, Corba, etc.)
- 누구든 이것을 지키지 않으면 해고하겠다.

넷플릭스에서 오픈소스로 개발한 아키텍처 패턴 및 OSS (Netflix OSS)
우리는 해당 시스템을들 이용하여 상대적으로 편하게 마이크로 서비스를 구현하면 됨
'Program > Software Architect' 카테고리의 다른 글
| [마이크로서비스 3] 마이크로 서비스 capabailties 모델 (0) | 2024.08.15 |
|---|---|
| [마이크로서비스 2] 마이크로 서비스 장/단점 (0) | 2024.08.12 |
| 실용주의 프로그래머 Topic 51 실용주의 시작 도구 (0) | 2024.07.25 |
| gcc sysroot 옵션을 이용한 opencv 크로스컴파일 (0) | 2024.07.17 |
| 마틴 파울러 SW Architecture 정리 (0) | 2024.07.12 |