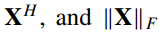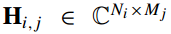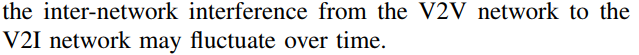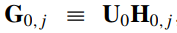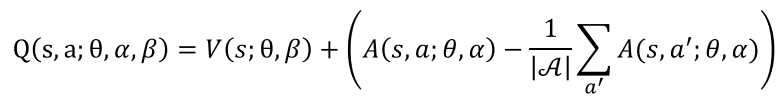전략(Strategy) 패턴 정의
알고리즘 구현 부분을 캡슐화하여 알고리즘의 변경과 수정에 용이한 패턴을 의미한다. 서브 클래스들의 핵심 알고리즘 구현 부분을 별도로 캡슐화하여 베이스 클래스와 서브 클래스 간의 상속으로 인한 결합성을 낮춘다.
핵심 : 베이스 클래스는 핵심 알고리즘의 호출 부분을 인터페이스로 저장하고 호출만수행하고, 핵심 알고리즘의 구현 부분을 캡슐화하여 코딩한다.
필요한 상황
1. 베이스 클래스를 상속 받은 서브 클래스들이 베이스 클래스의 함수를 호출할 때 각기 다른 기능을 수행하는 구조가 필요할 때 (다형성을 이용할 경우)
2. 서브 클래스가 베이스 클래스의 함수를 오버라이딩하여 서브 클래스에서 함수를 재작성 해야하는 경우 (매번 서브 클래스에서 함수를 오버라이딩하여 작성할 경우)
3. 향후 베이스 클래스를 상속받은 서브 클래스가 증가할 것으로 예상 될 경우 (잠재적 기능 추가 요소인 경우)
Class 다이어그램
요구 사항 1. RPG 게임 환경에서 검사, 수도승, 궁사 직업군이 있다.
요구 사항 2. 각 직업군은 서로 다른 공격과 방어 행동을 가진다.
요구 사항 3. 각 직업군은 무기 변경이 가능하다.

코드
1. 사람 Class (베이스 클래스)
public class Human
{
protected IAttackBehavior attackBehavior { get; set; }
protected IDefenceBehavior defenceBehavior { get; set; }
public void Attack()
{
attackBehavior.attack();
}
public void Defence()
{
defenceBehavior.defence();
}
public void SetAttackMode(IAttackBehavior ia)
{
this.attackBehavior = ia;
}
public void SetDefenceMode(IDefenceBehavior id)
{
this.defenceBehavior = id;
}
}2. 행동 interface
public interface IDefenceBehavior
{
void defence();
}
public interface IAttackBehavior
{
void attack();
}3. 알고리즘 구현 Class 부분 Behavior interface를 상속받음
public class AttackWithBow : IAttackBehavior
{
public void attack()
{
Console.WriteLine("Attack with Bow");
}
}
public class AttackWithSword : IAttackBehavior
{
public void attack()
{
Console.WriteLine("Attack with Sword");
}
}
public class AttackWithGlobe : IAttackBehavior
{
public void attack()
{
Console.WriteLine("Attack with Globe");
}
}
public class DefenceWithBow : IDefenceBehavior
{
public void defence()
{
Console.WriteLine("Defence with Bow");
}
}
public class DefenceWithSword : IDefenceBehavior
{
public void defence()
{
Console.WriteLine("Defence with Sword");
}
}
public class DefenceWithGlobe : IDefenceBehavior
{
public void defence()
{
Console.WriteLine("Defence with Globe");
}
}4. 전사, 궁사, 수도승 클래스 (서브 클래스)
public class Archer : Human
{
public Archer()
{
this.attackBehavior = new AttackWithBow();
this.defenceBehavior = new DefenceWithBow();
}
}
public class SwordMaster : Human
{
public SwordMaster()
{
this.attackBehavior = new AttackWithSword();
this.defenceBehavior = new DefenceWithSword();
}
}
public class Monk : Human
{
public Monk()
{
this.attackBehavior = new AttackWithGlobe();
this.defenceBehavior = new DefenceWithGlobe();
}
}5. Main 코드
Attack(new Archer());
Attack(new SwordMaster());
Attack(new Monk());
var instance = new Monk();
instance.SetAttackMode(new AttackWithBow());
Attack(instance);
void Attack(Human human)
{
human.Attack();
}
void Defence(Human human)
{
human.Defence();
}출력 결과

코드 설명
1. 사람 Class (베이스 클래스)
- 모든 서브 클래스들의 함수와 알고리즘 구현 인터페이스를 담고 있다.
- Class의 사용자는 서브 클래스들의 특징을 파악할 필요 없고 베이스 클래스의 함수와 특성값만 알면 된다.
2. 행동 interface
- 알고리즘 인터페이스이다.
- 베이스 클래스는 알고리즘 인터페이스 변수를 저장하고, 필요에 따라 인터페이스를 상속받은 다른 구현 알고리즘을 바꿔치기 사용하면 된다.
3. 알고리즘 구현 Class 부분 Behavior interface를 상속받음
- 알고리즘 인터페이스를 상속받은 Class이다.
- 실제 알고리즘의 구현이 들어가는 부분이다.
4. 전사, 궁사, 수도승 클래스 (서브 클래스)
- 생성자 부분에서 행동 interface 규격을 맞추는 Class로 정의하여 베이스 클래스의 행동 interface에 할당하면 된다.
5. Main 코드
- Main에 정의한 함수는 사람 class의 함수를 호출하지만 각 서브 클래스들로 업캐스팅하여 기입하고 각 서브 클래스들은 각기 다른 행동 interface로 구성했기 때문에 서로 다른 출력 결과를 보여준다.
- 출력 결과 모든 요구사항을 충족함을 볼 수 있다.
설명 보충을 위한 그림 자료

필요에 따라 추가 설명
1. 베이스 클래스를 상속받아 서브 클래스에서 재사용하는 경우 고려하면 좋다.
2. 상속구조에 의한 베이스 클래스와 서브 클래스 간의 코드 변경에 의한 의존성이 줄어든다.
3. 단 interface라는 추상화 구조가 필요하다.
4. 알고리즘을 사용하는 Class는 interface형 변수를 담고 있다가 필요시 interface에서 정의한 함수를 호출하는 방법이다.
정리 및 결론
1. 전략 패턴의 핵심은 베이스 클래스가 특정 interface를 변수로 저장하고 있다가 특정 interface를 상속받은 구현 알고리즘 Class를 변수처럼 사용하는 것
2. 전략 패턴은 서브 클래스에서 베이스 클래스에 구성되어 있는 특정 interface를 원하는 구현 알고리즘으로 할당시킨다.
3. 베이스 클래스를 이용하는 코드(Main 부분)는 베이스 클래스의 함수만 호출해도 다양한 구현 알고리즘을 구성할 수 있다.
4. 객체지향적 사고 팁
- 변하는 부분은 캡슐화한다. (추가 및 변경이 용이하도록 하는 것)
- 상속보다는 구성을 이용하면 결합성을 낮출 수 있다. (베이스 클래스가 특정 interface를 변수로 저장하는 것)
- 직접 구현보다는 interface를 상속받은 구현 Class로 나눠 변수처럼 사용한다.
'Program > SW Design Patterns' 카테고리의 다른 글
| CH5 데코레이터 패턴 (1) | 2023.03.05 |
|---|---|
| CH4 팩토리 패턴 (0) | 2023.03.04 |
| CH3 옵저버 패턴 (0) | 2023.03.03 |
| CH2 싱글턴 패턴 (0) | 2023.03.02 |
| 개요 (0) | 2023.03.01 |