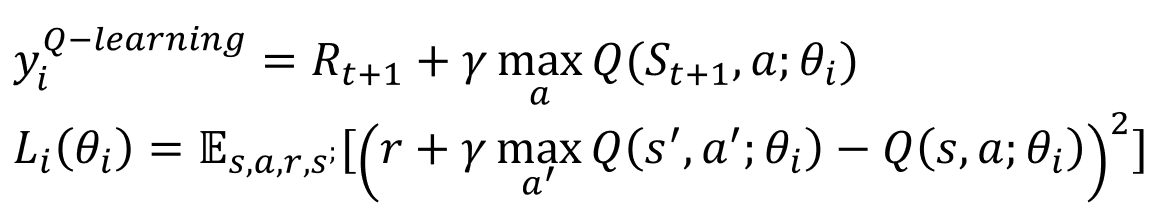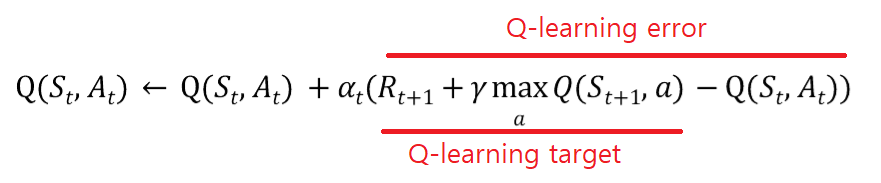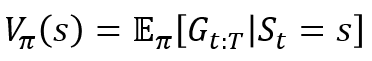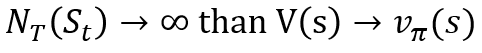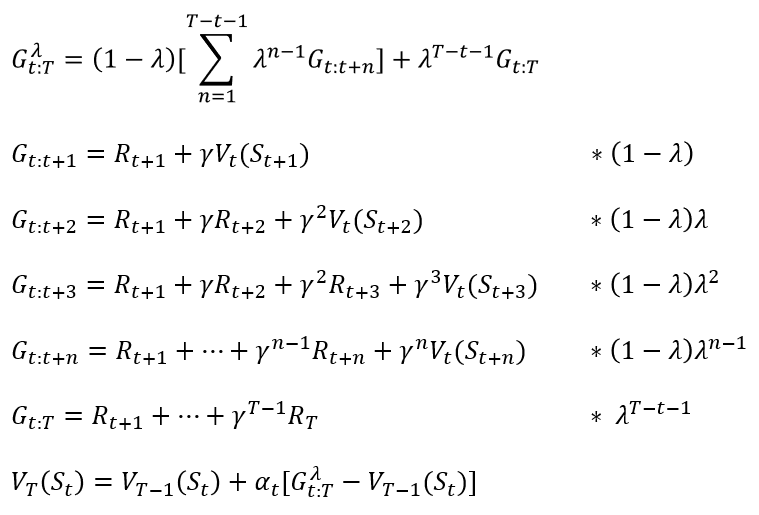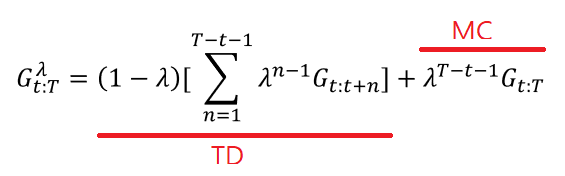- Deep Q Network가 이전의 심층 강화학습의 어떤 문제를 어떻게 해결했는지 이해한다.
- Deep Q Network의 동작 방식을 이해하고 코드를 다룰 줄 안다.
- Deep Q Network의 한계점을 이해한다.
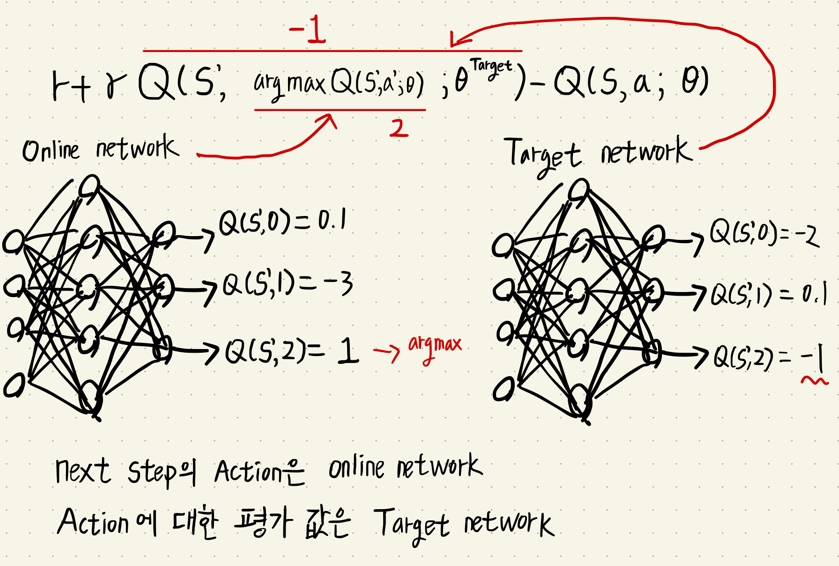
DQN trick 1 - Target Network
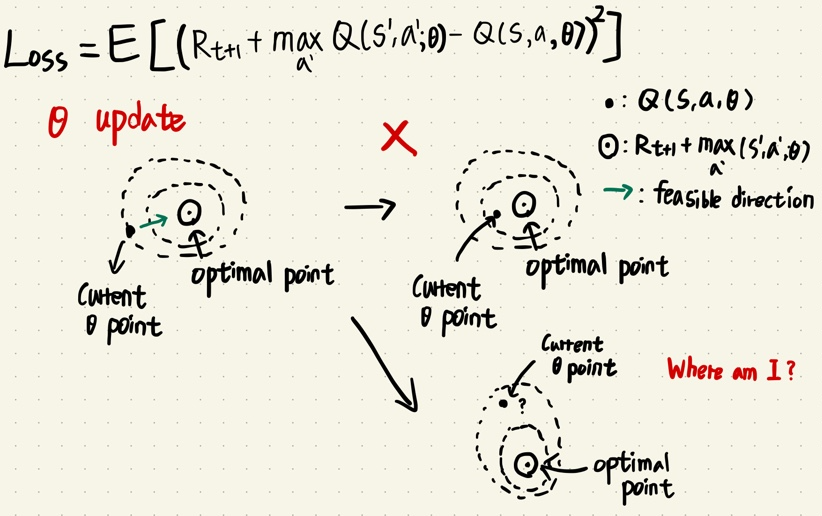
- 기존 NFQ의 문제점은 Neural Network 가 update 하면서 next state의 Q function값이 동시에 업데이트 하면서 결론적으로 불안정한 업데이트 Loss 값이 생긴다.
- 새롭게 제안한 Target network를 도입한 update 식
- 학습할때에는 target network는 k번의 학습 스탭마다 current network의 파라미터를 복사하고, k 번의 학습 스탭 동안 current network의 파라미터 값만 업데이트 하는 방법이다.
- 복잡한 환경일 수록 많은 학습 스탭이 필요하다. (아타리 게임 같이 CNN이 포함되어있는 모델은 10,000스텝 단위, 카트폴 환경 같이 직관적인 환경은 10~20 스텝 단위)
def optimize_model(self, experiences):
states, actions, rewards, next_states, is_terminals = experiences
batch_size = len(is_terminals)
#target model의 Q function 값을 이용
max_a_q_sp = self.target_model(next_states).detach().max(1)[0].unsqueeze(1)
target_q_sa = rewards + (self.gamma * max_a_q_sp * (1 - is_terminals))
#online model의 Q function 값을 이용
q_sa = self.online_model(states).gather(1, actions)
td_error = q_sa - target_q_sa
value_loss = td_error.pow(2).mul(0.5).mean()
self.value_optimizer.zero_grad()
value_loss.backward()
self.value_optmizer.step()
def update_network(self):
# 특정 학습 스텝이 지나면 online model의 파라미터를 target model의 파라미터로 복사함
for target, online in zip(self.target_model.parameters(), self.online_model.parameters()):
target.data.copy_(online.data)
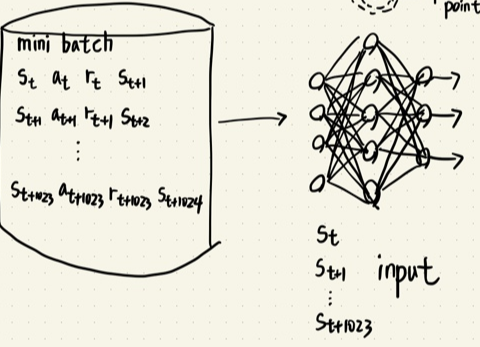
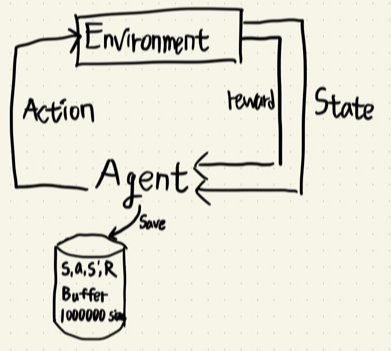
DQN trick 2 - Experience replay
- 기존 NFQ에서 update에 사용한 데이터 셋은 IID 가정을 성립시키기 힘들었다.
- 업데이트 하는 미니배치 데이터셋은 모두 시간 관계성(순차적으로 들어오는 데이터)이 있었다.
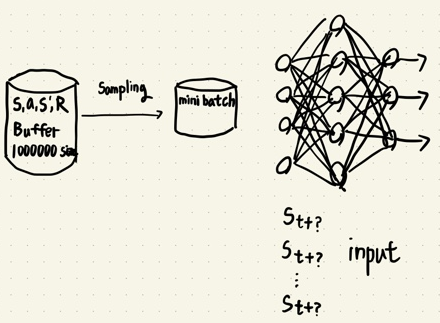
- experience replay buffer 구조를 이용하여 IID 가정을 어느 정도 성립시키고, 데이터 튜플들간의 시간 관계성을 제거했다.
- 이 문제를 해결 하기위해 experience replay buffer 구조를 이용하여 state, action, reward, next state 튜플을 모두 저장하고 학습 Phase에서 experience replay buffer에서 mini batch 사이즈만큼 튜플을 샘플링하여 학습하는 방법을 사용했다.
experience replay buffer에 데이터를 모으는 과정
experience replay buffer에서 mini batch 사이즈만큼 샘플링 후 Network 학습
- Deep Neural Network를 이용한 Q - function근사화 방법을 이해하고 구현한다. (2 종류의 DNN)
- 기존의 TD 방법을 DNN의 학습 방법으로 매칭 시키며 이해하고 설명 가능해야 한다.
기존 MC-control, TD(Q-learning, SARSA) control의 한계점
- 기존의 MC-control, TD control은 table 형태로 저장하여 Value function 또는 Action value function을 업데이트하고 저장했다.
- 하지만 이 방법의 근본적인 문제는 table 형태로 모든 state에 대해서 각 Value function과 Action value function을 저장하고 있어야 한다는 문제점이 있었다.
- 따라서 State가 연속적인 값이거나 많은 State로 구성된 Environment인 경우에는 비현실적으로 매우 많은 state를 기억하고 있어야 하는 문제가 있었다.
Deep neural network의 도입
DNN 예시 사진
- 지도 학습에서 많이 쓰이는 Neural network 구조이다.
- 기존의 perceptron 메커니즘을 조합하여 구성한다.
Perceptron 예시
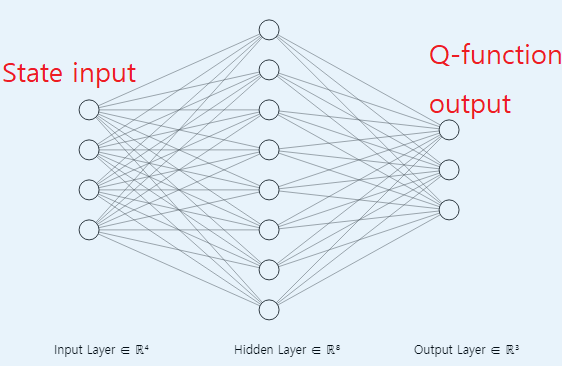
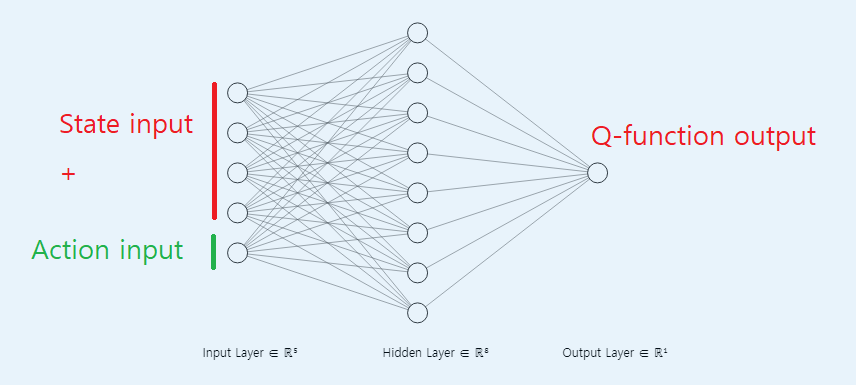
- 이번에 소개하는 NFQ는 2가지 타입의 DNN 구조를 이용하여 Q-function approximation을 한다.
Type1. State input, Q-function outputType2. State, action input, Q-function output
- 두 타입 모두 추 후 사용하게 될 구조임으로 강화 학습에 DNN을 어떻게 적용했는지 숙지해야 한다.
- DNN Class 정의 코드 (pytorch 이용)
class FCQ(nn.Module):
def __init__(self,
input_dim,
output_dim,
hidden_dims=(32,32),
activate_fc=F.relu):
super(FCQ,self).__init__()
# 활성화 함수 설정 (보통 ReLu 사용)
self.activation_fc = activate_fc
# 입력 레이어 정의
self.input_layer = nn.Linear(input_dim, hidden_dims[0])
# 은닉 레이어 설정 (여러 Layer 등록을 위해 List로 정의)
self.hidden_layer =nn.ModuleList()
# 반복문을 이용하여 여러 Layer를 등록함.
for i in range(len(hidden_dims) - 1):
hidden_layer=nn.Linear(hidden_dims[i], hidden_dims[i+1])
self.hidden_layer.append(hidden_layer)
# 출력 레이어 정의
self.output_layer = nn.Linear(hidden_dims[-1], output_dim)
# 모델에 입력시 사용할 함수
def forward(self, state):
# state 입력
x = state
# state 값이 torch.Tensor 타입이 아닐 경우 변환
if not ininstance(x, torch.Tensor):
x = torch.Tensor(x, device=self.device, dtype=torch.float32)
x = x.unsqeeze(0)
# 입력레이어 통과후 활성화 함수 적용
x = self.activation_fc(self.input_layer(x))
# 은닉레이어 통과후 활성화 함수 적용 반복
for hidden_layer in self.hidden_layers:
x = self.activate_fc(hidden_layer(x))
# 출력레이어 통과
x = self.output_layer(x)
# 결과값 출력
return x
- 다음은 Loss 함수에 대한 설명이다. 간단하게 MSE(mean squared error)를 사용한다.
# 다음 state의 Q function을 모두 가져옴
q_sp = self.online_model(next_states).detach()
# 다음 state의 Q function들 중 최대값을 가져옴
max_a_q_sp = q_sp.max(1)[0].unsqeeze(1)
# Q function target을 계산함.
target_q_s = rewards + self.gamma * max_a_q_sp * (1 - is_terminals)
# 현재 state의 Q function 값을 가져옴. 이때 모델은 입실론 그리디 정책으로 행동을 선택을 기준으로함.
q_sa = self.online_model(state).gather(1, actions)
# E [ (Q function target - Q function) ^ 2 ]
MSELoss(target_q_s, q_sa)
- 입실론 그리디 정책을 기반으로 학습시킨다.
class EGreedyStraregy():
...
def select_action(self, model, state):
self.exploratory_action_take = False
with torch.no_grad():
q_values = model(state).cpu().detach().data.numpy().squeeze()
if np.random.rand() > self.epsilon:
action = np.argmax(q_values)
else:
action = np.random.randint(len(q_values))
return action
- Optimizer 함수는 Adam, RMSProp 등이 있다.
- 주로 미니 배치 단위로 S, A, R, S'을 모으고 배치 단위로 학습시킨다.
정리
NFQ의 한계점(중요)
- 동일한 DNN을 이용하여 학습을 시킨다. 즉 현재 state, action 값에 대해서 학습을 하면서 다른 state, action값의 바뀐다.
미니 배치 단위로 학습을 하면서 target으로 하는 state, action 짝만 학습시키려고 함으로써 다른 비슷한 state, action 값이 안정적으로 수렴하지 힘들다.
- IID(independent and identically distribution) 가정을 지키기 못한다. 미니 배치 단위로 모델을 학습시킨다. 하지만 미니배치 학습을 주기로 매번 Q-function 값이 달라지게된다. 이는 매 주기마다 수집하는 미니배치 샘플들이 서로 다른 분포에서 샘플링된다는 뜻이다.
- 미니배치 데이터들이 시간 관계성이 있다. DNN 모델을 시간 관계가 있는 데이터를 기반으로 학습 시킨다면 오버피팅 된다. (Q-function approximation 기능을 RNN이나 LSTM으로 대체 한다면 괜찮을 지도..?)
def q_learning(env,
gamma=1.0,
init_alpha=0.5,
min_alpha=0.01,
alpha_decay_ratio=0.5,
init_epsilon=1.0,
min_epsilon=0.1,
epsilon_decay_ratio=0.9,
n_episodes=3000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
Q = np.zeros((nS, nA), dtype=np.float64)
Q_track = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda state, Q, epsilon : np.argmax(Q[state]) \
if np.random.random() > epsilon \
else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in tqdm(range(n_episodes), leave=False):
state, done = env.reset(), False
#현재 state는 agent의 policy를 이용해서 선택
action = select_action(state, Q, epsilons[e])
while not done:
next_state, reward, done, _ = env.step(action)
# Q-learning target 계산, 다음 state는 다음 상태의 Q값에서 최대값 선택
q_target = reward + gamma * Q[next_state].max() * (not done)
# Q-learning error 계산
q_error = q_target - Q[state][action]
# Q값 update
Q[state][action] = Q[state][action] + alphas[e] * q_error
state = next_state
Q_track[e] = Q
pi_track.append(np.argmax(Q, axis=1))
V = np.max(Q, axis = 1)
pi = lambda s: {s:a for s, a in enumerate(np.argmax(Q, axis=1))}[s]
return Q, V, pi, Q_track, pi_track
Double Q-Learning
- Q-learning의 고질적인 문제인 overestimation 문제가 있다.
- 그 결과 maximazation bias 현상이 일어난다. (Q-learning 로직 특성상 다음 상태의 max 값을 적용하는 경향 때문.)
- 2개 이상의 Q(S,A) 매칭 값을 두고 sum, avg, min 값 들을 고려하여 Q(S,A) 값을 개선하는 방법이다.
- double learning 의 기반이다.
- double deep Q - network 의 기반이다.
import numpy as np
def double_q_learning(env,
gamma=1.0,
init_alpha=0.5,
min_alpha=0.01,
alpha_decay_ratio=0.5,
init_epsilon=1.0,
min_epsilon=0.1,
epsilon_decay_ratio=0.9,
n_episodes=3000):
nS, nA = env.observation_space.n, env.action_space.n
pi_track = []
#2개의 Q 값 생성
Q1 = np.zeros((nS, nA), dtype=np.float64)
Q2 = np.zeros((nS, nA), dtype=np.float64)
Q_track1 = np.zeros((n_episodes, nS, nA), dtype=np.float64)
Q_track2 = np.zeros((n_episodes, nS, nA), dtype=np.float64)
select_action = lambda Q, state, epsilon np.argmax(Q[state]) if np.random.random() > epsilon else np.random.randint(len(Q[state]))
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
epsilons = decay_schedule(init_epsilon, min_epsilon, epsilon_decay_ratio, n_episodes)
for e in tqdm(range(n_episodes), leave=False):
state, done = env.reset(), False
while not done:
# 2개의 Q 값에 대한 평균으로 Q값을 형성하고 선택함.
action = select_action(state, (Q1+Q2)/2, epsilon[e])
next_state, reward, done, _ = env.step(action)
# 2개중 1개의 Q 값을 랜덤으로 선택하여 업데이트함.
if np.random.randint(2):
argmax_Q1 = np.argmax(Q1[state])
#이때 다른 Q 값을 보고 가져와서 업데이트함.
td_target = reward + gamma * Q2[next_state][argmax_Q1] * (not done)
td_error = td_target - Q1[state][action]
Q1[state][action] = Q1[state][action] + alphas[e] * td_error
else:
argmax_Q2 = np.argmax(Q2[state])
#이때 다른 Q 값을 보고 가져와서 업데이트함.
td_target = reward + gamma * Q1[next_state][argmax_Q2] * (not done)
td_error = td_target - Q2[state][action]
Q2[state][action] = Q2[state][action] + alphas[e] * td_error
state = next_state
Q_track1[e] = Q1
Q_track2[e] = Q2
pi_track.append(np.argmax((Q1+Q2)/2), axis=1))
Q = (Q1 + Q2) / 2.0
V = np.max(Q, axis = 1)
pi = lambda s: {s:a for s, a in enumerate(np.argmax(Q, axis=1))}[s]
return Q, V, pi, (Q_track1 + Q_track2)/2., pi_track
정리
- Control problem을 위해 Q-function을 prediction 하는 방법을 배웠다.
- Q-function을 prediction 하는 method로 MC-control, SARSA, Q-learning, Double Q-learning을 배웠다.
- MC-control 은 MC 방법 기반으로 variance가 크고 에피소드 끝까지 기다려야 하는 단점이 있지만 bias가 다른 적다.
- SARSA 는 TD 방법 기반으로 on-policy 방법이다. 이유는 현재 policy로 다음 state에 대한 action을 선택하고 평가하고 Q 값을 업데이트 하기때문이다. on-policy 방법은 off-policy 방법에 비해 안정적이다. 하지만 직접 경험해야 하는 문제가 있다.
즉 다른 agent의 평가값을 반영하지 않는다.
- Q-learning은 TD 방법 기반으로 off-policy 방법이다. 이유는 다음 state에 대한 action은 현재 policy를 따르지 않고 max Q 값만을 이용해 학습하기 때문이다. off-policy 방법은 불안정하지만 다른 agent의 평가값을 반영할 수 있기 때문에 학습 데이터를 이용하는데 유연하다.
- Double Q-learning은 TD 방법 기반이고 off-policy 방법이다. Q-learning의 단점인 overestimation, maximization bias 문제를 해결하기 위해 2개 이상의 Q 값을 이용해 평균을 내서 평가하는 방법이다.
1. 심층 강화학습 기반 V2V communication에서 분산형 자원 할당 메커니즘을 제안함.
2. unicast 와 broadcast 시나리오에 모두 적용 가능함.
3. 강화학습 agent의 action은 (sub-band, power level) 쌍으로 수행함.
4. 강화학습 agent는 global information을 기다리지 않음. (wait time이 없다.)
5. global information을 기다리지 않기 때문에 전송 오버헤드만 발생한다.
6. 시뮬레이션 결과는 강화학습 agent가 효과적으로 V2V link의 제약조건을 만족하고 V2I link의 SINR을 높여줌 (V2V link에 의한 Interference를 최소화 시킴.)
Introduction
1. V2V 통신의 quality of service (qos) 요구 사항은 초저 지연 및 신뢰성임.
2. 근접 한 장치 기반 D2D 통신은 대기 시간과 에너지 소비를 크게 줄이면서 직접 로컬 메시지 전파를 제공하므로 3GPP는 V2V 통신의 QoS 요구 사항을 충족하기 위해 D2D 통신을 기반으로 V2V 서비스를 지원함.
3. D2D 링크와 셀룰러 링크 간의 상호 간섭을 관리하기 위해서 최적의 Resource allocation 메커니즘이 필요함.
4. V2V 통신 분야에서 이동성이 높은 차량에 의해 해결해야할 문제가 있음.
5. 차량의 높은 이동성은 무선 채널이 빠르게 변화하기 때문에 채널 상태 정보(CSI) 추정은 적용하기 힘듬.
6. D2D 기반 V2V 통신의 문제를 해결하기 위해 다양한 Resource allocation 방식이 제안되어 왔음.
7. 대부분 V2V 통신 메커니즘은 중앙 집중식(centralized manner)으로 수행됨.
8. 각 차량은 로컬 채널 상태 및 간섭 정보 포함한 로컬 정보(local information)을 중앙 제어자(central controller)에게 전송하고 중앙 제어자(central controller)는 최적의 선택을 수행함. 여기서 선택이란 RB index와 전송 전력을 의미함.
9. 하지만 그럼에도 불구하고 최적화 문제는 일반적으로 NP-hard 한 상태에 놓임.
10. 대안 솔루션으로 문제를 여러 단계로 나누어 각 단계에 대해 로컬 최적(optimal) 또는 준최적(sub-optimal)한 선택을 수행했음.
11. 중앙 제어자 (central controller)를 이용한 방법은 차량의 local information을 중앙에 전송해야 하기 때문에 차량의 수가 많아 질수록 transmission overhead가 증가하게됨. 따라서 이는 네트워크 확장을 방해함.
12. 따라서 이 논문은 네트워크 정보를 수집하는 중앙 제어자(central controller)를 안쓰고 분산 자원 할당 메커니즘(decentralized resource allocation mechanisms)을 제안함.
13. 분산 자원 관리 방법은 지원 인프라가 중단되어도 차량 끼리 동작할 수 있기때문에 효율적임.
14. 최근에는 V2V 통신을 위한 일부 분산 자원할당 메커니즘이 개발되어 왔음.
15. 이전의 방법은 차량 네트워크에서 유니캐스트 통신을 위해 제안되어 왔음.
16. 그러나 일부 V2V 통신 매커니즘은 구체적인 정보 전달 목적지가 없었음.
17. 현실적으로 V2V 통신에서 전달하는 메시지들은 인접한 차량들이 포함되어야함.
18. 따라서 unicast 방식보다 broadcast 방식이 안전 정보를 공유하는것이 적절함.
19. 하지만 맹목적으로 메시지를 broadcast 하면 broadcast strom 문제를 야기함.
20. 이런 문제를 해결하는 논문은 [9, 10]임. 이는 statistical 또는 topological 정보를 기반으로 broadcast protocol이 연구되어 왔음.
21. 이전 연구의 V2V 링크의 QoS는 SINR의 신뢰성만을 포함했음.(제약 조건이라 하기에는 부족함)
22. 이전 연구들은 latency 제약조건은 공식화하기 어려워서 고려를 못했었음.
23. 본 논문은 unicast and the broadcasting 차량 통신에서 resource allocation을 처리 하기위해 Deep Reinforcement Learning을 사용함.
24. [23]번 논문은 virtualized vehicular networks 에서 복잡한 공동 자원 최적화 문제를 Deep Reinforcement Learning을 사용하여 해결함.
25. 본 논문은 로컬 CSI 및 interference level 를 포함한 local observation 정보를 통해 resource allocation을 하기 위해 Deep Reinforcement Learning을 사용함.
26. unicast 시나리오에서 각 V2V Link는 강화학습 agent로 간주하고, 각 time slot 별로 이웃 차량과 공유되는 교환 정보 및 즉각적인 채널 상태를 관측한 후에 spectrum과 transmission power를 선택함.
27. unicast case는 Deep Reinforcement Learning 프레임워크를 broadcast 시나리오에 확장하여 적용할 수 있음.
28. 일반적으로 강화학습 Agent는 V2I 링크에 대한 V2V 링크의 간섭을 최소화는 것과 동시에 V2V 링크의 제약 조건(latency)를 충족하기 위해 학습함. (V2I 링크 SINR 증가 + V2V 링크의 제약 조건 만족)
29. 이 작업의 일부(unicast, broadcast)는 [12, 13]논문에 published 됨.
30. 이 논문은 unicast, broadcast 프레임워크를 모두 통합함.
31. 또한 Deep Reinforcement Learning 기반 resource allocation scheme을 잘 이해할 수 있도록 실험 결과 데이터를 공유하고 논의함.
32. 논문의 핵심 기여는?
- V2V 링크의 대기 시간 제약을 해결하기 위해 Deep Reinforcement Learning을 기반으로 decentralized resource
allocation 매커니즘을 처음으로 제안함.
- V2V resource allocation 문제를 해결하기 위해 unicast, broadcast 시나리오 모두 state, action, reward를 설계함.
- 시뮬레이션 결과를 바탕으로 Deep Reinforcement Learning 기반 resource allocation은 V2I 링크와 V2V 링크가 채널
을 공유하는 최적의 방법을 학습함.
33. 2장에서 unicast V2V 통신을 위한 시스템 모델을 소개함.
34. 3장에서 unicast V2V 통신을 위한 강화학습 기반 resource allocation 프레임워크를 설명함.
35. 4장에서 기존의 프레임워크를 broadcast 시나리오로 확장함. 단 메시지 수신자가 고정된 영역 내의 모든 차량인 경우.
36. 5장에서 시뮬레이션 결과를 제시함.
37. 6장은 결론을 제시함.
System model for unicast communication
1. 이 섹션에서는 unicast 통신에서 resource management problem을 소개함.
2. fig1 의 M 개의 cellular users(CUEs)는 아래 사진과 같이 노테이션을 정의함.
3. fig1 의 K 개의 쌍으로 형성된 V2V users(VUEs)는 아래 사진과 같이 노테이션을 정의함.
4. CUEs는 V2I link를 VUEs는 V2V link를 사용하는데, V2V link는 traffic safety management를 하기 위해 VUEs 끼리 정보를 공유하는데 사용하고, V2I link는 CUEs가 기지국(BS)과 높은 데이터량을 통신하는데 사용함.
5. 주파수 효율성을 높이기 위해, 기지국(BS)에서 겪는 interference가 더 제어 가능하고, uplink의 resource 가 덜집중적으로 사용되기 때문에 V2I link(uplink)를 직교(orthogonally)로 할당된 상향링크(uplink) 스펙트럼을 형성하고 이는 V2V link와 공유 하게됨.
6. m 번째 CUE의 SINR 공식은 식 (1)과 같음.
아래 노테이션의 왼쪽은 m 번째 CUE가 선택한 전력을 의미, 오른쪽은 k 번째 VUE가 선택한 전력을 의미함.
아래 노테이션은 noise power 임.
아래 노테이션은 m 번째 CUE가 기지국(BS)로 신호를 전송할때 생기는 Channel gain임 (송신 차량 안테나 게인, 수신 기지국 안테나 게인, Large scale fading, Small scale fading 등이 적용)
아래 노테이션은 k 번째 VUE의 Channel gain임. (송신차량 안테나 게인, 간섭 수신 기지국 안테나 게인, 송신 차량과 기지국간의 RB에서 형성된 Largs scale fading, Small scale fading 등이 적용)
아래 노테이션은 k 번째 VUE가 m 번째 CUE와 동일한 RB를 선택했는지 유무를 의미함. (0 또는 1), 따라서 동일한 RB를 선택한 경우에만 Interference를 적용함.
7. m 번째 CUE의 Channel capacity는 다음과 같음. (2), 계산 결과는 보통 bit 로 계산됨.
아래 노테이션은 sub carrier bandwith임.
아래 노테이션은 m 번째 CUE의 SINR임.
log 는 log_2 임.
8. k 번째 VUE의 SINR 공식은 (3)과 같음.
아래 노테이션은 k 번째 VUE 가 전송할 전력임.
아래 노테이션은 k 번째 VUE 가 V2V link를 통해서 전송할때 생기는 Channel gain임.(송신 차량 안테나 게인, 수신 차량 안테나 게인, Large scale fading, Small scale fading 등이 적용).
아래 노테이션은 Noise power 임.
아래 식은 동일한 RB를 사용하는 CUE에 의해 생기는 interference 임. m개의 RB중에 k번째 VUE가 m번째 RB를 선택한 경우 summation 안에 첫번째 값이 1이 되고 그 이후에는 m 번째 CUE가 선택한 전력과 Channel gain에 의해 간섭이 생기는 뜻을 가짐.
아래 노테이션은 k 번째 VUE가 m 번째 RB를 선택했는지 여부임. (0 또는 1)
아래 노테이션은 m 번째 CUE가 전송한 전력임.
아래 노테이션은 m 번째 CUE와 k 번째 간에 형성된 Channel gain임 (송신 차량 안테나 게인, 수신 차량 안테나 게인, Large scale fading, Small scale fading 등이 적용)
아래 식은 동일한 RB를 사용하는 VUE에 의해 생기는 interference 임. 2개의 summation 안에 첫번째, 두번째 변수가 현재 자신 k와 다른 모든 차량 k'에 대해서 동일한 RB를 선택한 경우 1이되어 k' 번째 VUE이 선택한 전력과 Channel gain의 영향을 받음으로써 interference가 증가함을 의미함.
아래 노테이션은 k 번째 VUE가 m 번째 RB를 선택했는지 여부임. (0 또는 1)
아래 노테이션은 k' 번째 VUE가 m 번째 RB를 선택했는지 여부임. (0 또는 1)
아래 노테이션은 k' 번째 VUE가 전송한 전력임.
아래 노테이션은 k' VUE에서 k VUE간에 형성된 Channel gain(k 번째 송신 차량 안테나 게인, k'
번째 수신 차량 안테나 게인, Large scale fading, Small scale fading 등이 적용)임. 선택한 RB에 따라 다름. 논문에서는 power gain이라 부름.
9. k 번째 VUE의 Channel capacity 는 다음과 같음(6)
아래 노테이션은 sub carrier bandwith임.
아래 노테이션은 k 번째 VUE의 SINR임.
log 는 log_2 임.
10. V2V link의 data rate를 그렇게 중요하지 않음. 다만 latency 제약조건을 맞춰야함.
즉 latency 요구사항을 충족할만큼의 data rate만 충족하면 됨.
11. 이와 같은 조건은 Deep Reinforcement Learning 의 framework에서 reward function을 reward로 주면됨.
latency 제약 조건 위반시 -reward, latency 제약 조건 충족시 +reward, V2I link의 data rate가 높을 경우 + reward
12. 기지국(BS)는 V2V link에 대한 정보가 없기 때문에 V2I link의 자원할당(RB, 전송 전력 선택)에 대한 자원 관리는 독립적임. 즉 기지국(BS)는 독립적으로 I2V, V2I를 수행함. 이는 V2V link가 Given condition 일때 강화학습 agent는 스스로 최적의 RB와 전송 전력을 선택해야함을 의미함!
13. 분산 자원 관리(decentralized resource management) 시나리오에서 V2V link는 local observation 정보 기반으로 RB와 전송 전력을 선택함.
14. resource allocation을 위해 observation 해야하는 데이터는 첫번째로 channel information 과 interference information 이다.
15. RB의 수는 V2I link의 수 M 과 같다고 가정한다.
16. 아래 노테이션은 t time slot에서 각 V2V link가 모든 RB에 대해서 수신차량에 반영될 instantaneous channel information (power gain 이라 함) 이다.
17. 아래 노테이션은 t time slot에서 관측한 V2I link가 RB에서 관측한 channel information임. 즉 V2I link에서 차량과 기지국(BS)간에 형성된 채널 정보임. (power gain 이라고 함)
18. 아래 노테이션은 t -1 time slot에서 수신된 interference signal 세기임. (V2V link에 의한 interference + V2I link에 의한 interference)
19. 아래 노테이션은 t - 1 time slot에서 근접한 차량이 선택한 RB 횟수 정보임. 만약 근접 차량 3대가 같은 RB를 선택한 경우 3 값이 나옴.
20. 아래 노테이션은 전송해야할 메시지의 상태를 의미함.
첫번째로 t time slot에서 전송 대기시간 만기까지 남은 시간임.
두번째로 t time lost에서 남은 데이터 비트의 비율을 의미함.
21. 위에서 정의한 노테이션이 broadcast 시나리오에서 강화학습 agent의 state로 정의 됨.
22. 단 unicast 시나리오에서 강화학습 Agent의 state는 아래와 같음.
23. 위와 같이 state 별로 최적의 action을 매핑해야 resource allocation을 잘 성공시킬 수 있으나, 종종 네트워크를 분석하기에는 힘듬. 따라서 Deep Reinforcement Learning 이 필요함.
Deep Reinforcement Learning for Unicast Resource Allocation
1. 이번장은 Deep Reinforcement Learning 기반 unicast 시나리오에서 V2V 통신을 소개함.
2. Fig2와 같이 강화학습 framework는 agent, environment로 구성하고 상호작용을 하는 구조이다.
3. unicast 시나리오에서 V2V 링크는 강화학습 agent로 간주하고, 이외의 모든 것은 environment로 간주한다.
4. 분산된 환경에서는 다른 V2V link의 동작을 제어할 수 없기 때문에 각 강화학습 agent는 RB, 전송 전력 등과 같은 집합적으로 나타나는 환경 조건을 기반으로 한다. 즉 모든 V2V link의 action을 수집하여 environment에 가한다는 뜻임.
5. Fig2와 같이 t time slot 별 V2V link 강화학습 agent는 environment로 부터 observation한 state를 관찰함.
6. 관찰한 state를 기반으로 action space의 항목 중 1개롤 선택하여 작업을 수행함.
7. 이 모든 것은 Q-function을 내장하는 Deep neural network에 의해 결정됨.
8. 강화학습 agent가 취한 action에 따라 environment로 부터 받는 next state가 영향을 받음. 그리고 reward를 받음.
9. 논문의 reward는 V2I link의 데이터 비트 양, V2V link의 데이터 비트 양, 대기 시간 제약까지 남은 시간에 의해 결정됨.
10. 2장에서 논의한 바와 같이 각 V2V link 강화학습 agent가 관찰 가능한 상태는 여러개로 구성됨.
11. 최종적으로 상태는 아래와 같음.(자세한 설명은 2장에서 했음.)
12. state는 heterogeneous data로 구성되어 있지만 DNN이 데이터에서 유용한 정보를 추출하여 최적의 정책을 학습할 것임. (heterogeneous data란 서로 다른 속성을 가지는 데이터를 의미함. 예시 dBm 데이터와 선택유무 index 의 쌍 등..)
13. 각 time slot 마다 강화학습 agent는 정책(policy)에 따라 현재 state를 기반으로 RB와 전송전력을 선택할 것임.
14. 전송 전력은 3 level(23dBm, 10dBm, 5dBm) 로 구성됨. 따라서 action space는 3 x RB의수 가 됨. (이 는 DQN을 가능하게한 원리임)
15. V2V resource allocation의 목적은 다음과 같음.
- V2V link는 모든 V2I link와 다른 V2V link에 대해 interference를 최소화하는 resource allocation을 해야함.
- 위의 조건을 만족함과 동시에 V2V link의 latency 제약 조건을 충족하기 위해 resource를 보존해야함.
16. 따라서 reward function은 목적과 동일해야함.
17. 논문의 reward 기능은 V2I link의 데이터 레이트, V2V link의 데이터 레이트 및 latency 제약 조건을 모두 만족하도록 설계 해야함.
18. V2I link 및 V2V link의 총 데이터 레이트는 각각 V2I link 및 기타 V2V link에 대한 간섭을 측정하는데 사용됨.
19. latency 조건 만족 실패율은 패널티로 표시됨.
20. 결과적으로 보상함수는 다음과 같음(특정 노테이션은 위에서 정의함.) (7)
21. 아래 노테이션들은 reward의 가중치를 의미함.
22. 아래 노테이션은 현재 만기 시간임(100ms).
23. 즉 재약 시간 만기까지 남은 시간에 만기 시간을 뺌으로써 시간이 적게 남을 수록 panalty 는 커지는 원리임.
24. long term으로 좋은 성능을 얻기위해 즉각적인 보상과 미래의 보상을 모두 고려해야함. (강화학습 특징임.)
25. 따라서 주요 목표는 시나리오가 끝날때까지 얻은 보상 기대값을 최대화 하는 정책을 찾아야함.
26. 그에 상응하는 공식은 다음과 같음.(8)
27. 아래 노테이션은 Discount factor 요소이고, 0~1 사이의 값을 가진다. 0에 가까울수록 미래의 보상 비율을 낮추는 것이고 1에 가까울 수록 미래의 보상 비율을 높이는 것이다.
28. state transition과 reward는 stochastic 으로 MDP가 모델링됨.(즉 시뮬레이션 환경이 확률적으로 설계된다는 뜻.)
29. 여기서 state와 next state의 천이 확률과 reward는 environment와 강화학습 agent의 action에 연결됨.
30. 확률 matrix는 다음과 같음.
- 볼드체는 matrix를 의미함. 이 matrix는 여러 state와 각 state 별로 action에 대한 reward와 next state가 모두 기술되어 있는 matrix임. 이런 확률 matrix를 알면 사실 Dynamic Programming으로 풀면됨. 하지만 현실은 매우 많기 때문에 복잡도가 매우 높음.
31. 하지만 이런 transition matrix는 우리가 알 수 없음. 따라서 Model free 환경임.
32. 따라서 논문은 Environment를 직접 구성(Channel 정보, 차량의 위치, 속력 정보, 강화학습 agent 선택에 따르는 reward 계산 식 등..) 하여 강화학습 agent를 학습 시킴.
33. 강화학습 agent는 policy 기반으로 action을 선택한다.
34. policy는 state와 action을 mapping 한다.
35. action space는 V2V link에 대해 2차원으로 구성되어 있다. (RB index, power level)
36. Q-learning 알고리즘은 시뮬레이션에서 long-term expected accumulated discounted reward의 최대화 하는데 쓰인다.
37. Q-value는 state-action pair로 있을때 해당 state에서 action을 했을때 기대 할 수 있는 expected accumulated discounted reward이다.
38. Q-value는 state, action pair가 주어지면 다음과 같은 방법을 통해 action을 선택하여 개선된 policy를 구한다.
39. Q-value에 대한 optimal Q 값을 구하는 최적의 정책은 다음 업데이트 방정식을 기반으로 구할 수 있다.
이는 벨만 방정식 기반으로 만들어진 공식이다.
40. 추가 설명을 하자면 아래 노테이션은 TD error를 의미한다.
41. TD target 은 다음과 같다.
42. Q-learning은 Q-value를 TD-target 값과 근사화하는 것이 목표이다. 즉 TD-error을 줄이면서 TD-target에 가까워지는데
TD-target과 비슷하다는 뜻은 현재 state 기점에서 시나리오가 끝났을때 얻을 수 있는 expected return값에 가까워진다는 뜻이다.
43. 아래 노테이션은 learning rate 이다.
44. resource allocation 시나리오에서 훈련을 통해 최적의 policy를 찾으면 V2V link에 대한 RB와 전송 전력을 선택하여 V2I link + V2V link의 전체 데이터 레이트를 최대화 하고, V2V link의 latency 제약 조건을 보장하는데 강화학습 agent를 사용 할 수 있음. (policy는 강화학습 agent가 state를 받았을때 어떤 행동을 할지 매핑되어있는 한 룩업테이블임.)
45. 고전적인 Q-learning은 state수가 적을때 loog-up table을 이용해 state와 Q-value가 매핑되어있는 것을 사용할 수 있음.
46. 하지만 V2V 통신을 위한 resource management의 state와 action의 space가 커지면 기존의 Q-learning 방법은 적용할 수 없음.
47. 이유는 많은 수의 state가 자주 방문을 못하고 그에 따라 Q-value가 업데이트 하기 힘들기 때문임.
48. 이 문제를 해결 하기위해 Deep Neural Network(DNN)을 사용하여 Q-value를 approximation 함.
49. DNN은 대량의 데이터를 기반으로 state에 따르는 Q-value를 매핑하는 기능을 함. 즉 매우 많은 state를 받아도 Q-value를 근사화해서 보여준다는 뜻임.
50. Q-network의 weight θ값은 각 iteration 마다 다음 loss function을 최소화하기 위해 update됨.
51. 본 논문의 시뮬레이션은 Train phase와 Test phase가 있음.
52. train, test 데이터는 모두 Enviroment와 강화학습 agent가 상호작용 하여 생성됨. (Environment의 다이나믹스를 알기때문에 가능함. 3GPP 36.885에 있음.)
53. Deep Q-Network를 최적화하는데 train data 는 state, action, reward, next state로 구성됨.
54. environment 시뮬레이터는 VUE, CUE 을 다루는 채널을 포함하며, 차량의 위치를 무작위로 생성하고 V2V link 및 V2I link의 CSI 정보는 차량의 위치, 속력정보에 따라 생성됨.
55. 일반적으로 위에서 정의한 data tuple은 experience replay buffer에 저장시킴.
56. Algorithm 1 에서 볼 수 있듯이 train phase 에서 experience replay buffer에서 미니 배치 데이터를 꺼내서 Deep Q-Network를 학습 시킴(weightθ값을 update함).
57. 위 방법은 DNN을 학습시킬때 시간적 상관관계를 제거할 수 있음. (DNN을 학습시키기 위한 유명한 트릭임.)
58. Algorithm2 에서 볼 수 있듯이 Test phase에서는 학습한 Q-network를 따라 주어진 최대 Q-value를 선택하여 action을 수행함.
59. 강화학습 agent는 local information 기반으로 독립적으로 선택하기 때문에 다른 V2V link와 동시에 action을 수행할 경우 다른 V2V link의 action에 대해서 알지 못함.
60. 결과적으로 V2V link에서 강화학습 agent가 action을 할때 environment을 완전히 파악하지 못함. (이유 다른 V2V link가 동일한 RB를 선택할 수 도 있기때문)
61. 이 문제를 해결하기 위해 강화학습 agent는 V2V link에 대해서 전체 집합이 있다면 하위 집합으로 쪼개어 각 time slot에서 쪼개어 비동기식으로 작업을 업데이트 하도록 설정함. (즉 모든 V2V link의 강화학습 agent가 동시에 선택하는 것이 아니라 하위 집단으로 쪼개어 순서대로 선택한다는 뜻임.)
62. 이렇게 함으로써 앞서 action을한 하위 집단의 V2V link 강화학습 agent의 선택을 미리 관측함으로써 기존의 문제를 해결할 수 있음.
63. coordinations은 자신의 행동을 근접한 차량과 action을 공유하고 차례로 결정을 내리도록 허용해야 도입가능함. (Multi -agent의 필요이유)
64. coordinations은 독립적으로 선택하는 것이아니라 공동으로 action을 수행함으로써 좋은 효과를 얻을 수 있음. (즉 각 차량들은 서로의 action을 관측 가능해야 좋은 결과를 얻을 수 있다는 뜻.)
65. 분산 resource allocation 문제에서 각 V2V link의 강화학습 agent가 독립적으로 선택하면 동일한 RB를 많이 선택하게 되는 결과를 초래할 수 있음. 즉 interference가 증가하게 될수도 있음.
66. 따라서 강화학습 agent는 이웃하는 차량들의 V2V link 강화학습 agent의 action을 보고 선택해야 많은 V2V link 강화학습 agent가 동일한 RB를 선택하는 문제를 피할 수 있음. 즉 interference를 감소 시킬 수 있다는 뜻임.
67. 따라서 비동기식으로 강화학습 agent가 action을 취하는 것은 좋은 성능을 얻는데 유리함.
Resource Allocation For Broadcast System
1. 이번장은 Deep Reinforcement Learning 기반 resource allocation 구조에서 기존의 unicast 시나리오에서 broadcast 시나리오로 확장한다.
2. 이번장은 broadcast 시스템을 위한 프레임워크를 공식화하고 Deep Q-Network를 훈련하기 위한 알고리즘을 소개할 것임.
3. fig 4 처럼 V2I 링크를 사용하는 CUEs는 다음과 같은 노테이션을 사용한다.
4. 그리고 V2V 링크를 사용하는 VUEs는 다음과 같은 노테이션을 사용한다.
5. VUE는 메시지를 broadcasting 하며, 각 메시지는 주변 영역에 하나의 송신기와 수신기 그룹이 있음.
6. unicast의 경우 유사하게 V2I link에 대해 uplink 주파수 대역은 V2V link에 의해 재사용함.
7. 이는 uplink 자원이 덜 집중적으로 사용되고 BS에서 interference 을 제어 가능하기 때문임.
8. broadcast의 reliability를 높이기 위해 각 차량은 수신한 메시지를 rebroadcast 함.
그러나 1장에서 언급한 바와 같이 boradcast storm 문제는 차량의 밀도가 크고 네트워크의 과도한 중복 재방송 메시지가 존재하는 경우를 발생 시킴.
9. 이 문제를 해결하기 위해 차량은 수신된 메시지의 적절한 하위집합을 선택하여 rebroadcast 를 해야함.
그래야 더 많은 수신기가 네트워크에 중복 방송을 거의 가져오지 않으면서 latency 제약 대기 시간 내에서 메시지를 받을 수 있음.
10. V2I link의 SINR과 Channel capacity 는 아래와 같음. (모두 unicast 시나리오에서 설명했기 때문에 생략.)
11. V2V link의 SINR 공식과 Channel capacity는 아래와 같음. (모두 unicast 시나리오에서 설명했기 때문에 생략.)
12. decentralized setting에서 각 차량은 broadcast 할 메시지를 결정하고 RB를 잘 사용해야함.
13. 이런 결정은 local observations 기반으로 하며 V2I link와 독립적으로 수행되어야함.
14. 따라서 V2I link이 resource allocation을 먼저 수행한 후에 VUE에 대한 latency 제약 조건을 만족하고 CUE에 대한 VUE의 간섭이 최소화되어야 함을 보장하는 것이 중요.
15. RB 선택 및 메시지 스케줄링은 local observation에 따라 관리 되어야함.
16. unicast 시나리오일때 사용했던 local information 외에도 차량이 동일한 메시지를 수신한 횟수, 방송한 차량까지의 최소 거리 등 일부 정보는 broadcast 시나리오에서 유용하게 쓰일 수 있음. (아래 노테이션은 (왼쪽)broadcast 송신 차량과의 거리, (오른쪽)동일한 메시지를 수신한 횟수 임.)
17. 일반적으로 차량에서 메시지를 여러 번 들었거나 이전에 메시지를 방송한 다른 차량과 차량이 가까이 있으면 메시지를 재방송할 확률이 낮아짐. 즉 위의 노테이션값이 커지면 재방송할 확률이 낮아지는것임.
18. broadcast 시나리오에서 각 차량은 시스템 Agent로 간주함.
19. t timeslot에서 차량은 state를 관찰하고 이에 따라 policy에 따라 RB와 메시지를 선택하는 행동을 함.
20. 강화학습 agent의 action에 따라 next state로 전환이 되고, V2I link, V2V link의 데이터 레이트와 V2V link의 latency 제약 충족 여부에 따라 reward를 받음.
21. unicast 시나리오와 유사하게 state를 정의했다. 다만 broadcast는 아래 설명과 같이 조정되었다.
- 해당 차량 agent가 메시지를 수신한 횟수
- 해당 차량 agent에게 broadcast한 차량과의 최소 거리
22. 이를 정리하면 state는 다음과 같다.
23. 각 t timeslot 별 강화학습 agent는 broadcast를 위한 메시지와 RB를 결정해야함.
24. 각 메시지에 대한 action space는 RB의수 + 1 이다.
25. 강화학습 agent가 첫번째 RB로 action을 하면 해당 RB에서 broadcasting을함.
그렇지 않으면 강화학습 agent가 마지막으로 action을 하는 경우 메시지를 broadcast하는 것을 못함. (모르겠음..)
26. unicast 시나리오와 유사하게 강화학습 agent의 목적은 VUE에 대한 latency 제약 조건 충족과 V2I link에 대한 interference를 최소화 하는 것임.
27. reward 는 unicast와 동일함. 하지만 rebroadcasting을 억제하기 위해 메시지를 수신하지 못한 수신자의 데이터 레이트만 계산함. (중복 계산 할 경우 증가하기 때문.)
28. 최적의 policy를 얻기 위해 Q-function를 근사화 하도록 Deep Q-Network를 학습함.
29. broadcast 시나리오를 위한 tran, test code는 Algorithm 3, 4에 보듯이 unicast와 유사함.
4. 차량들은spatial Poisson process에 따라 random 하게 위치 시킴.
5. 각 차량은 근처 3대의 차량과 V2V link를 형성함.
6. 따라서 V2V link는 차량 갯수의 3배로 형성함.
7. Deep Q-Network의 layer는 5개로 구성함. hidden layer는 3개이며 각 500, 250, 120 으로 구성됨.
8. 활성화함수를 Relu function을 이용함 (DNN 구조에서 많이 사용함.)
9. learning rate는 0.01 이고 학습이 진행됨에 따라 지수적으로 감소시킴.
10. exploration과 exploitation의 균형을 맞추기 위해 epsilon-greedy policy를 사용함 (epsilon 확률로 random action 수행)
11. Optimizer는 Adam을 사용함.
12. 자세한 파라미터는 TABLE1에 기술되어 있음.
13. 제안한 방법은 2개의 방법과 비교함. (random, Ashraf)
14. fig 5 는 증가하는 차량수 대비 V2I link의 channel capacity 이다. 차량의 증가에 따라 V2V link의 수가 증가하고 결과적으로 V2I link에 대한 간섭이 증가함으로 V2I link의 channel capacity는 감소한다. 제안한 방법이 다른 방법에 비해 좋은 성능을 냈다.
15. fig 6 은 증가하는 차량대비 Latency 제약 조건 충족 확률이다. 마찬가지로 증가하는 차량 개수 대비 충족확률이 떨어짐을 볼 수 있다. 하지만 제안하는 방법이 다른 방법에 비해 성능이 좋음을 확인했다.
16. Deep Reinforecement Learning 기반이 우수한 성능을 낸 것에 대한 이유를 찾기 위해 fig 7. 과같이 남은 시간 대비 강화학습 agent 가 선택한 전송 전력을 분석했다.
17. 흥미로운 것은 남은 시간이 적을 수록 가장 높은 전송 전력을 선택할 확률이 높았었다. 이는 latency 제약 시간 만기 까지 얼마 남지 않았을 때 V2V의 latency 제약 조건을 만족하기 위해 최대 전력을 선택한 것으로 보인다.
18. 10ms 미만 남았을때 강화학습 agent는 높은 확률로 위반되고 더 낮은 전력으로 전환하여 다른 시간이 남은 V2V link 와 V2I link의 Channel capacity를 늘리기 위한 선택을 했다.
19. 따라서 논문의 Deep Reinforecement Learning 기반 접근 방식이 기존 다른 방법들에 비해 state, reward 간에 implicit relationship을 특성화하도록 학습 한 것으로 추론할 수 있다.
20. broadcast 시나리오는 각 차량이 일정 거리 내에서 다른 모든 차량과 통신한다는 점을 제외하면 unicast 시나리오와 동일한 환경임.
21. k 번째 VUE의 메시지는 수신 차량의 SINR 임계값보다 높으면 수신차량이 성공적으로 수신된 것으로 간주함.
22. 메시지의 모든 대상 수신자가 성공적으로 메시지를 수신한 경우 이는 V2V 전송이 성공한 것으로 간주함.
23. Deep reinforcement learning 기반 방법은 scheduling 과 channel selection을 동시에 하지만 이전 연구들은 이 둘을 별개로 취급해서 수행함.
24. Fig8. 은 차량 갯수 대비 V2I link의 데이터 레이트임. 제안 하는 방법이 성능이 더 좋음.
25. Fig9. 은 차량 갯수 대비 V2V link의 latency 제약 조건 만족 확률임.
26. 제안한 Deep Reinforcement Learning 방법은 unicast 시나리오, broadcast 시나리오 비교 대상 대비 모두 좋은 성능을 냄.
27. 기존의 방법들은 이런 관계들을 특성화 하기 어려웠음. 하지만 제안한 Deep Reinforcement Learning 방법은 fig 7과 같이 남은 시간에 따라 선택하는 전송 전력을 전략적으로 수행했음. 하지만 이게 대단한 이유가 남은 시간과 보상 함수 사이의 관계는 명시적으로 공식화 할 수 없음에도 불구하고 이런 특성을 스스로 찾았기 때문임.
28. 따라서 Deep Reinforcement Learning 은 local information 기반으로 resource allocation을 잘하는 것을 증명함.
29. DNN 기반의 방법의 주요 관심사 중 하나는 계산 복잡성임. 본 논문은 GPU 1080 Ti 에서 구동 했을때 0.00024 초 걸림.
차량에 대한 latency 제약 조건에 비하면 매우 적은 시간임. 때문에 이 속도는 허용됨.
30. 또한 가중치를 이진화하는 것과 같은 모델 경량화, 최적화 등에 대한 선행작업이 있음. 이를 하면 더욱 빠른 action 선택을 할 수 있을 것임.
31. 제안된 접근 방식의 복잡성을 줄이기 위한 연구 방향이 될 것임.
Conclusion
1. 본 논문은 V2V 통신에서 decentralized resource allocation mechanism을 Deep Reinforcement Learning를 이용해 문제를 해결 한 것을 제안함.
2. 이 방법은 unicast, broadcast 모두 적용 가능한 것을 보여줌.
3. 또한 global information이 필요 없기 때문에 transmission overhead가 적음.
4. 시뮬레이션 결과는 Deep Reinforcement Learning method가 V2V 통신 환경에서 decentralized resource allocation을 잘하는 것을 보여줌.
- State transition matrix, 모든 State, Reward를 모르는 상황이다.
-> Agent가 직접 탐색을 해야하는 상황임.
- 내가 관심있는 강화 학습은 Model free 환경이다.
-> 현실 세계는 Model free라 생각한다. 현실은 매우 다양한 환경요소 때문에 확률적으로 매우 분산이 큼.
- Model free 환경에서 현재 policy에 따르는 Value Function을 평가해야 한다.
-> Value Function을 구하면 현재 policy를 따랐을 때 얻을 수 있는 expected return 값을 매 state 마다 구할 수 있다.
Model free 환경에서 policy를 평가하는 2가지 방법
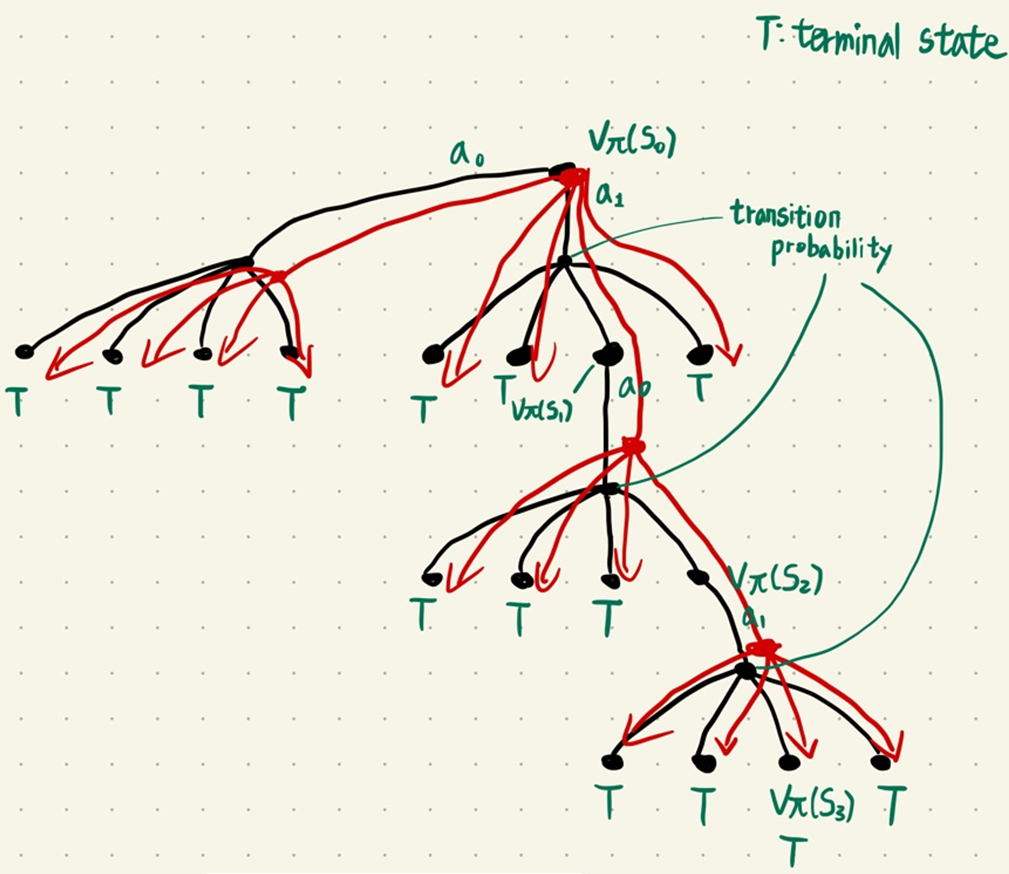
Monte Carlo prediction(MC)
- First-visit MC
1. Value function은 현재 state부터 termianl state까지의 감가율을 적용한 expected return 값이다.
2. MC 방법을 통해 무한대에 가까운 시뮬레이션을 할 경우 Value function 값은 현재 policy의 value function에 수렴한다. (하지만 수렴이 힘들고 분산이 클 것임 -> state, action, reward, next state로 구성된 tuple 집단이 유사한 trajectory를 구하는 것은 힘들다는 뜻)
많은 Terminal state, 많은 trajactory, 실제 환경에서는 얼마나 많을까..?
3. 좀 더 효율적으로 계산하기 (모든 trajectory를 기억하지 않고, episode가 끝날 때마다 update 하기)
4. 독립적이면서 동일한 분포(independent and identically distributed, IID)에서 trajectory를 형성함으로써 무한개의 tracjtory value-function이 수렴하는 것을 확인 가능.
- Every-visit MC
1. First-visit MC를 공부하다보면 1개의 trajectory에서 2번 이상 같은 state에 방문한다면 어떻게 해야할까? First-visit MC 방법을 고집할까? 아니면 다시 계산할까?
2. 이런 문제를 다루기 위해 Every-visit MC가 있다.
3. IID 는 아니지만 수렴함을 확인함.
4. trajectory 생성 함수
def generate_trajectory(pi, env, max_steps=200):
done, trajectory = False, []
while not done:
state = env.reset()
for t in range(max_steps)
action = pi(state)
next_state, reward, done, _ = env.step(action)
experience = (state, action, reward, next_state, done)
trajectory.append(experience)
if done:
break
state = next_state
return np.array(trajectory)
5. MC prediction 함수
def mc_prediction(pi,
env,
gamma=1.0,
init_alpha=0.5,
min_alpha=0.01,
alpha_decay_ratio=0.5,
n_episodes=500,
max_steps=200,
first_visit=True):
#모든 state의 갯수를 가져옴
nS = env.observation_space.n
#감가 계수 미리 계산 0.99 ~ 0.3695
discounts = np.logspace(0, max_steps, num=max_steps, base=gamma, endpoint=False)
#decay하는 alpha 값도 미리 계산
alpha = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
#value-function 초기화
V = np.zeros(nS, dtype=np.float64)
#episode 별 value-function을 보기위함.
V_track = np.zeros((n_episodes, nS), dtype=np.float64)
#dictionary로 state 별 value function을 저장함.
targets = {state:[] for state in range(nS)}
for e in tqdm(range(n_episodes), leave=False):
#1개의 trajectory 생성
trajectory = generate_trajectory(pi, env, max_steps)
#방문 여부 판단용 변수
visited = np.zeros(nS, dtype=np.bool)
#1개의 trajectory 순회
for t, (state, _, reward, _, _) in enumerate(trajectory):
#현재 state 방문 여부 & first_visit 모드인 경우 continue
if visited[state] and first_visit:
continue
#현재 state는 첫 방문이거나, every_visit 모드 인 경우 수행
visited[state] = True
#현재 상태부터 종료 상태까지 step 갯수를 샘
n_steps = len(trajectory[t:])
#Discount를 적용한 return 값을 계산함.
G = np.sum(discounts[:n_steps] * trajectory[t:, 2])
#targets 자료구조에 Discount를 적용한 return 값 저장
targets[state].append(G)
#mc error 계산 (현재 tracjtory에서 나온 value function - 기존의 value function)
mc_error = G - V[state]
#alpha 감가율을 적용하여 mc_error 적용
V[state] = V[state] + alphas[e] * mc_error
#trajectory 별 value function의 변화를 확인하기 위해 저장
V_track[e] = V
#최종 Value function, trajectory 별 value function, state 별 추론한 모든 기대값 반환
return V.copy(), V_track, targets
6. MC prediction의 단점은 에피소드가 끝날 때까지 기다려야함. (그렇다면 무한 에피소드인 경우??)
7. 장점은 bias에 강함
Temporal-Difference (TD)
1. 단일 step 에서 얻은 Reward 만을 이용하여 Value-function을 추론한다.
2. MC는 에피소드가 끝날때까지 기다려야 하지만 TD는 즉각적으로 계산한다.(bootstrapping)
- bootstrapping
현재의 값을 이용해 미래의 값을 추정하는 방법.
3. TD의 Value-function 구하기 공식
4. Value-function이 현재 state로 부터 기대할 수 있는 return 값이라 하는 것은 변함없고 다음 step의 reward와 감가율을 적용한 공식을 재귀적으로 문제를 해결하였다.
5. TD target과 TD error
- TD target 은 현재 Value-function이 근사 해야하는 값이다.
- TD error 는 현재 Value-function과 TD target의 오차를 의미한다.
def td(pi,
env,
gamma=1.0,
init_alpha=0.01,
min_alpha=0.01,
alpha_decay_ratio=0.5,
n_episodes=500):
#state space 취득
nS = env.observation_space.n
#Value funcion 초기화
V = np.zeros(nS, dtype=np.float64)
V_track = np.zeros((n_episodes, nS), dtype=np.float64)
#TD target 초기화
targets = {state:[] for state in range(nS)}
#감소하는 alpha값 미리 계산
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
for e in tqdm(range(n_episodes), leave=False):
state, done = env.reset(), False
while not done:
#현재 state을 policy에 따라 action
action = pi(state)
#다음 state, reward, done 여부 취득
next_state, reward, done, _ = env.step(action)
#td target 계산
td_target = reward + gamma * V[next_state] * (not done)
#state에 따르는 td_target 저장
targets[state].append(td_target)
#td_error 계산
td_error = td_target - V[state]
#td_error에 alpha 값 적용후 value-function 없데이트
V[state] = V[state] + alphas[e] * td_error
#다음 state로 update
state = next_state
#V-function의 변화 양상 저장
V_track[e] = V
return V, V_track
- n-step TD
- MC 방법과 TD 방법은 서로 극단적인 성향을 가지고있다.
- MC는 episode가 끝나야하고, TD는 1단계의 step만 수행하고 가치를 평가한다.
- 결과적으로 MC는 low bias, high variance, TD는 high bias, low variance 하게 가치를 평가한다. (무한한 샘플링이 가능하다면 둘다 결국 수렴함.)
- MC와 TD 사이의 방법중 하나로 n-step TD가 있다.
간단하게 현재 state의 value function 값을 2개 step 이상의 discount factor가 적용된 reward로 적용하는 것이다.
def n_step_td(
pi,
env,
gamma=1.0,
init_alpha=0.5,
min_alpha=0.01,
alpha_decay_ratio=0.5,
n_step=3,
n_episodes=500):
#state 공간
nS = env.observation_space.n
#Value function 초기화
V = np.zeros(nS, dtype=np.float64)
#episode 별 value function 히스토리 저장
V_track = np.zeros((n_episodes, nS), dtype=np.float64)
#에피소드별 감소하는 alpha 값 미리 계산
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_epsidoes)
#Discount factor 미리 계산
discount = np.logspace(0, n_step + 1, num=n_step + 1, base=gamma, endpoint=False)
for e in tqdm(range(n_episodes), leave=False):
#state, done 여부, n-step 저장을 위한 path 초기화
state, done, path = env.reset(), False, []
#episode가 끝날때까지 실행
while not done or path is not None:
path = path[1:]
#n-step만큼 step 할때까지 반복 실행
while not done and len(path) < n_step:
action = pi(state)
next_state, reward, done, _ = env.step(action)
experience = (state, reward, next_state, done)
path.append(experience)
state = next_state
if done:
break
# 현재 path에 저장한 경험의 수
n = len(path)
# 평가할 state
est_state = path[0][0]
# path에 저장해왔던 reward만 추출
rewards = np.array(path)[:,1]
# 모든 reward에 discount factor 적용
partial_return = discount[:n] * rewards
# 다음 state의 value function값
bs_val = discounts[-1] * V[next_state] * (not done)
# td target 구하기, discount factor를 적용한 reward에 다음 state의 value function 합하기
ntd_target = np.sum(np.append(partial_return, bs_val))
# td error 구하기
ntd_error = ntd_target - V[est_state]
# td error에 현재 episode에 맞는 alpha 값 적용 후 저장
V[est_state] = V[est_state] + alphas[e] * ntd_error
if len(path) == 1 and path[0][3] == True:
path = None
V_track[e] = V
return V, V_track
- forward-view TD(λ)
- MC 방법과 TD 방법을 섞은 방법이다.
- λ 값을 0 보다 크고 1 보다 작은 사이의 값을 두면 MC 방법과 TD 방법을 동시에 가중치를 두고 쓰는 방법이다.
- λ 값이 0 이면 MC의 방법을, 1 이면 TD의 방법을 사용하는 것이다.
- 하지만 이 방법은 MC 방법과 동일한 문제점인 value function을 추정하는데 있어서 에피소드가 끝날때까지 기다려야하는 문제가 있다.
- backward-view TD(λ)
- forward-view TD 와 달리 eligibility trace 를 이용하여 MC와 TD의 개념을 섞어서 사용함
def td_lambda(
pi,
env,
gamma=1.0,
init_alpha=0.5,
min_alpha=0.01,
alpha_decay_ratio=0.5,
lambda=0.3,
n_epsidoes=500)
# 모든 state 취득
nS = env.observation_space.n
# Value function 초기화
V = np.zeros(nS, dtype=np.float64)
# episode 별 변하는 Value function 초기화
V_track = np.zeros((n_episodes, nS), dtype=np.float64)
# eligibility trace 배열 초기화
E = np.zeros(nS, dtype=np.float64)
# episode 별 감소하는 alphas 미리 계산
alphas = decay_schedule(init_alpha, min_alpha, alpha_decay_ratio, n_episodes)
for e in tqdm(range(n_episodes), leave=False):
# episode를 재시작 할때마다 eligibility trace를 0으로 초기화
E.fill(0)
# env reset
state, done = env.reset(), False
while not done:
action = pi(state)
next_state, reward, done, _ = env.step(action)
#td target 계산
td_target = reward + gamma * V[next_state] * (not done)
#td error 계산
td_error = td_target - V[state]
#현재 방문한 state에 대해서 eligibility trace 배열에 1을 더함
E[state] += 1
#현재 state에서 계산한 td error와 eligibility trace 배열을 모두 곱하고
#모든 state의 value-function에 적용
V = V + alphas[e] * td_error * E
# eligibility trace 배열 감가
E = gamma * lambda * E
state = next_state
V_track[e] = V
return V, V_track
- state를 재방문하는 횟수가 많을 수록 eligibility trace에서 배열의 값은 증가한다.
- 같은 state에 많이 방문 할 수록 큰 가중치로 업데이트 됨.
정리
- Model free 환경에서 value function을 prediction 하는 방법을 공부했다.
- 구하는 과정에서는 필연적으로 주어진 policy를 사용해서 trajectory를 형성해야 한다.
- 형성한 trajectory를 이용해서 MC 또는 TD 방법을 통해 value function을 prediction 했다.
- MC는 평가 하고자하는 state에서 시작하는 trajectory 를 여러개 형성하여 평균값을 통해 value function을 구했다. (bias 가 적은 대신 variance 가 큼)
- MC는 First visit, every visit 방법으로 나뉘고 두 방법은 모두 결론적으로 value-function이 수렴함을 볼 수 있다.
- TD는 평가 하고자 하는 state에서 바로 다음 state의 value function과 reward 만을 이용해서 value function을 구했다.(bias 가 큰 대신 variance 가 적음)
- TD는 n-step TD, forward-view TD(λ), backward-view TD(λ) 방법이 있는데 이 방법들은 모두 MC 방법의 특징과 TD 방법의 특징을 혼합하여 사용하기 위해서 사용되었다.