import math
import numpy as np
def get_pivot_position(tableau):
z = tableau[-1]
column = next(i for i, x in enumerate(z[:-1]) if x > 0)
restrictions = []
for eq in tableau[:-1]:
el = eq[column]
restrictions.append(math.inf if el <= 0 else eq[-1] / el)
row = restrictions.index(min(restrictions))
return row, column
def pivot_step(tableau, pivot_position):
new_tableau = [[] for eq in tableau]
i, j = pivot_position
pivot_value = tableau[i][j]
new_tableau[i] = np.array(tableau[i]) / pivot_value
for eq_i, eq in enumerate(tableau):
if eq_i != i:
multiplier = np.array(new_tableau[i]) * tableau[eq_i][j]
new_tableau[eq_i] = np.array(tableau[eq_i]) - multiplier
return new_tableau
def to_tableau(c, A, b):
xb = [eq + [x] for eq, x in zip(A, b)]
z = c + [0]
return xb + [z]
def simplex(c, A, b):
tableau = to_tableau(c, A, b)
while can_be_improved(tableau):
pivot_position = get_pivot_position(tableau)
tableau = pivot_step(tableau, pivot_position)
return get_solution(tableau)
def can_be_improved(tableau):
z = tableau[-1]
return any(x > 0 for x in z[:-1])
def is_basic(column):
return sum(column) == 1 and len([c for c in column if c == 0]) == len(column) - 1
def get_solution(tableau):
columns = np.array(tableau).T
solutions = []
for column in columns[:-1]:
solution = 0
if is_basic(column):
one_index = column.tolist().index(1)
solution = columns[-1][one_index]
solutions.append(solution)
return solutions
c = [1, 1, 0, 0, 0]
A = [
[-1, 1, 1, 0, 0],
[ 1, 0, 0, 1, 0],
[ 0, 1, 0, 0, 1]
]
b = [2, 4, 4]
solution = simplex(c, A, b)
print('solution: ', solution)
- GUI 프로그램에서 상태에 따라 버튼의 Enable, Disable 등 여부를 바꾸고 싶을 때
- 상태 변수를 switch로 넣어서 case로 때려 넣은 코드가 있을 때 (리펙토링 대상!!)
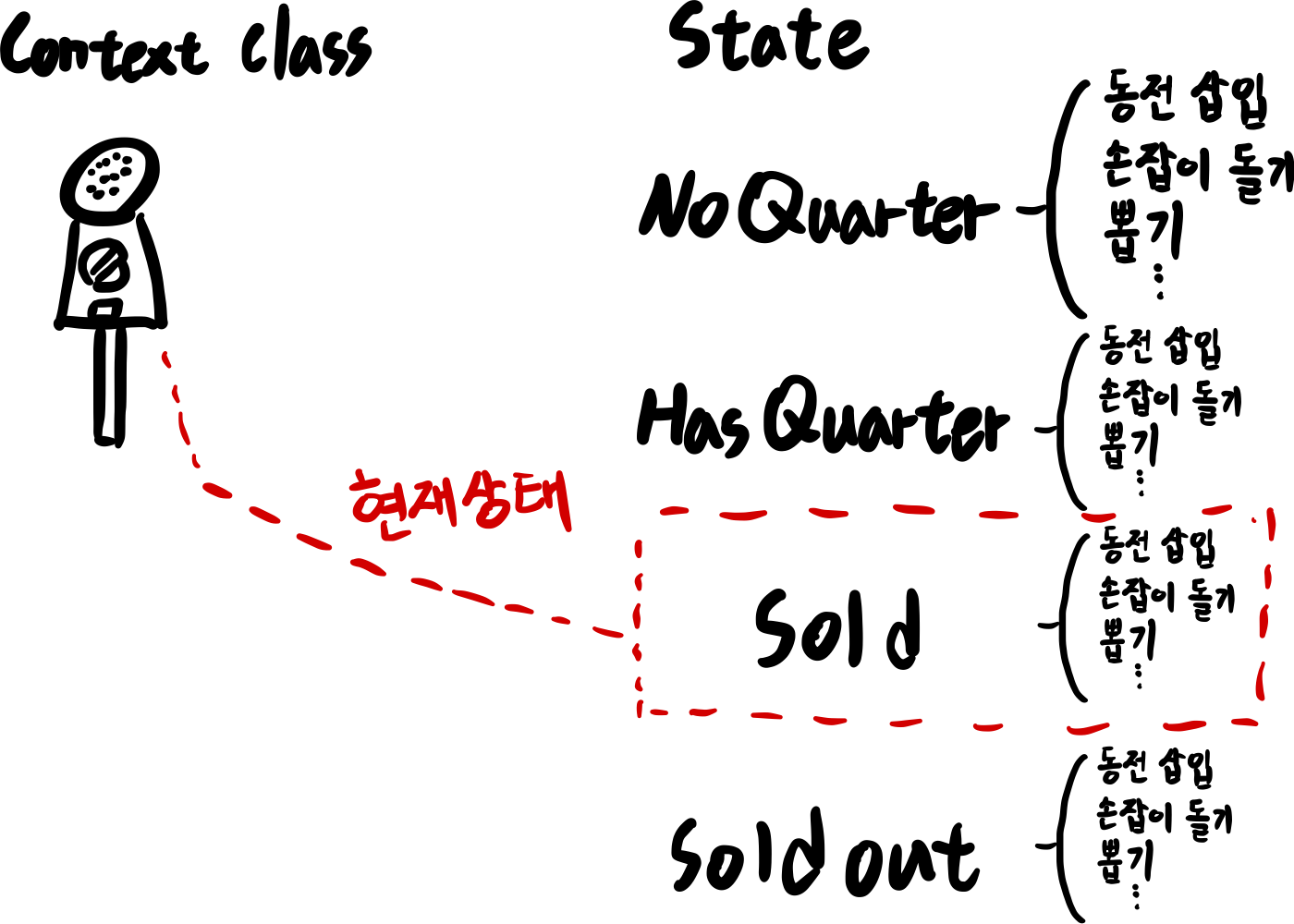
Class 다이어그램
스테이트 패턴
코드
스테이트 패턴
public interface State {
void insertQuarter();
void ejectQuarter();
void turnCrank();
void dispense();
}
public class HasQuarterSate : State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine)
{
this.gumballMachine = gumballMachine;
}
public void insertQuarter()=> Console.WriteLine("손잡이를 돌렸습니다.");
public void ejectQuarter(){
Console.WriteLine("동전이 반환됩니다.");
gumballMachine.setState(gumballMachine.noQuarterState);
}
public void turnCrank() => Console.WriteLine("손잡이를 돌렸습니다.");
public void dispense()=> Console.WriteLine("알맹이가 나갈수 없습니다.");
}
public class SoldState : State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine)
{
this.gumballMachine = gumballMachine;
}
public void insertQuarter()=> Console.WriteLine("잠깐만 기다려 주세요. 알맹이가 나가고 있습니다.");
public void ejectQuarter()=> Console.WriteLine("이미 알맹이를 뽑으셨습니다.");
public void turnCrank(){}=> Console.WriteLine("손잡이는 한 번만 돌려주세요.");
public void dispense(){
gumballMachine.releaseBall();
if ( gumballMachine.count > 0){
gumballMachine.setState(gumballMachine.noQuarterState);
}
else{
Console.WriteLine("더이상 동전이 없습니다");
gumballMachine.setState(gumballMachine.soldOutState);
}
}
}
public class SoldOutState : State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine)
{
this.gumballMachine = gumballMachine;
}
//인터페이스 구현체..
}
public class NoQuarterState : State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine)
{
this.gumballMachine = gumballMachine;
}
//인터페이스 구현체..
}
인터페이스와 구현체
public class GumballMachine {
State soldOutState {get;set;}
State noQuarterState{get;set;}
State hasQuarterSate{get;set;}
State soldState{get;set;}
State state = soldOutState;
int count {get;set;};
public GumballMachine(int numberGumballs){
soldOutState = new SoldOutState(this);
noQuarterState = new NoQuarterState(this);
hasQuarterSate = new HasQuarterSate(this);
soldState = new SoldState(this);
this.count = numberGumballs;
if (numberGumballs > 0){
state = noQuarterState;
}
}
public void insertQuarter(){
state.insertQuarter();
}
public void ejectQuarter(){
state.ejectQuarter();
}
public void turnCrank(){
state.turnCrank();
state.dispense();
}
public void dispense(){
state.dispense();
}
public void setState(State state){
this.state = state;
}
public void releaseBall(){
Console.WriteLine("A gumball comes rolling out the solt.....");
if (count != 0){
count = count - 1;
}
}
}
상태패턴을 이용하는 Context Class
코드 설명
스테이트 패턴
1. 인터페이스와 구현체
public interface State {
void insertQuarter();
void ejectQuarter();
void turnCrank();
void dispense();
}
Context Class에서 제공하는 기능을 인터페이스 함수로 대체했다.
public class HasQuarterSate : State {
GumballMachine gumballMachine;
public SoldOutState(GumballMachine gumballMachine)
{
this.gumballMachine = gumballMachine;
}
public void insertQuarter()=> Console.WriteLine("손잡이를 돌렸습니다.");
public void ejectQuarter(){
Console.WriteLine("동전이 반환됩니다.");
gumballMachine.setState(gumballMachine.noQuarterState);
}
public void turnCrank() => Console.WriteLine("손잡이를 돌렸습니다.");
public void dispense()=> Console.WriteLine("알맹이가 나갈수 없습니다.");
}
인터페이스의 구현체는 Context Class 인스턴스를 가지고 있으며, 인터페이스 구현체를 직접 실행하면서 상태 변경이 필요한 경우 Context Class 인스턴스의 상태를 직접 변경한다. 이부분에서 Context Class와의 종속성이 생긴다. (결합성이 올라감..)
2. 스테이트패턴을 이용하는 Context Class
Context Class는 스테이트 구현체들을 모두 가지고 있으며, 기능 실행이 필요할 때 인터페이스 구현체들의 함수만 호출한다.
설명 보충을 위한 그림 자료
스테이트 패턴
현재 상태 : HasQuarter, 상태별로 구현한 인터페이스 구현체들(슬롯 머신 기능 + 상태 천이 기능)
현재 상태 : Sold, 상태별로 구현한 인터페이스 구현체들(슬롯 머신 기능 + 상태 천이 기능)
필요에 따라 추가 설명
x
정리 및 결론
스테이트 패턴은 현재 프로그램의 상태에 따라 기능을 달리해야 할 때 적용할만한 패턴이다. 주요 특징은 아래와 같다.
1. 상태 인터페이스를 두고 그에 맞는 구현체들을 모든 상태 별로 구현한다.
2. 상태 인터페이스 구현체들은 온전히 자신의 기능만을 수행하며 상태 천이가 필요한 경우 Context Class의 상태 천이를 수행한다.
3. 전략 패턴과 유사하다.
개인적으로 상태 패턴을 실제로 사용한 사례를 보고싶다. 전략 패턴, 옵저버 패턴, 팩토리 패턴, 데코 패턴은 많이 쓰인다고 들었는데 상태 패턴을 사용하는 사례를 보지 못했다.
<cascade_dir_name> : 최종 검출기가 저장될 파일 이름 (최종 출력 확장자 .xml)
(일례 '-data result' 로 실행 시 result라는 폴더가 생성되고 result 밑에 cascade classifier들이 저장됨. 또한 현재 실행폴더에 result.xml이라는 이름으로 학습된 최종 검출기가 저장됨.)
<vec_file_name> : 앞서 생성 했던 학습 데이터 파일명 (확장자 : vec)
<background_file_name> : 검출할 이미지가 없는 이미지들이 기록되어있는 텍스트 file 이름 (negative 샘플이라한다.)
[<HARR, LBP, HOG>(default : HARR)]: 검출 모드 설정(옵션)
[<number_of_stages> (default : 20)] : 학습할 cascade 단계의 수. Cascade 검출기는 일련의 기본 검출기들로 구성되는데, Cascade 검출 방식은 먼저 1단계 classifier로 false들을 걸러내고, 나머지에 대해서는 2단계 classifier로 false들을 걸러내고, ... 이런식으로 해서 최종 단계까지 살아남으면 물체 검출에 성공한 것으로 간주함. -nstages는 이 단계수 즉, 기본 검출기들의 개수를 조절하는 것임. 학습된 각 단계별 기본 검출기들은 result\ 밑에 0, 1, 2, ... 밑에 텍스트 파일 형태로 저장됨.(옵션)
[-baseFormatSave (default : false)] : -featureType이 HAAR일 경우에만 의미를 가지는 파라미터임. 이 파라미터를 명시해 주면 훈련 결과를 예전의 Haar training 방식의 데이터 포맷으로 저장해줌. (옵션)
명령어 입력 예시
opencv_traincascade -data result -vec tr.vec -bg negative_list.txt -numPos 400 -numNeg 5000 -featureType HAAR -numState 14 -baseFormatSave
negative_list.txt 파일 구성은 아래와 같이 구성해야한다.
c:\negatives\img1.jpg
c:\negatives\img2.jpg
첫번째 인자 : 이미지 파일 경로
-npos: 각 cascade 학습 단계(stage)에 사용되는 positive 샘플 개수를 설정. 주의할 점은 .vec 파일에 있는 실제 샘플수를 입력하면 안됨. npos <= (vec파일에 있는 샘플수 - 100)/(1+(nstages-1)*(1-minhitrate))) 정도로 값을 주기 바람.
-nneg: 각 cascade 학습 단계(stage)에 사용될 negative 샘플 개수를 설정. -bg로 입력한 negative 이미지들 중에서다양한 위치 및 크기로 negative 샘플들을 뽑기 때문에 실제 negative 이미지 개수와 관계없이 원하는 값을 주면 됨.
-minhitrate: 각 cascade 단계의 기본 classifier들에게 요구되는 최소 검출율. 최종 검출기의 검출율은 minhitrate^nstages가 됨. 예를 들어, 기본값을 그대로 사용하면 최소 0.995^14 = 0.932 정도의 검출율을 가지는 detector를 얻을 수 있게 됨. 하지만 이것은 어디까지나 .vec 파일로 입력한 training 데이터에 대한 검출율이기 때문에 실제 일반적인 입력에 대한 검출율은 훨씬 떨어질 수 있음.
3. .xml 파일을 이용해 객체 검출 해보기
#include "opencv2/objdetect.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/videoio.hpp"
#include <iostream>
#include <string>
using namespace std;
using namespace cv;
void detectAndDisplay(const CascadeClassifier& classfier, Mat frame )
{
Mat frame_gray;
cvtColor( frame, frame_gray, COLOR_BGR2GRAY );
//-- Detect objects
std::vector<Rect> objects;
classfier.detectMultiScale( frame_gray, objects );
for ( size_t i = 0; i < objects.size(); i++ )
{
Point center( objects[i].x + objects[i].width/2, objects[i].y + objects[i].height/2 );
ellipse( frame, center, Size( objects[i].width/2, objects[i].height/2 ), 0, 0, 360, Scalar( 255, 0, 255 ), 4 );
}
//-- Show what you got
imshow( "Capture - object detection", frame );
}
int main(void)
{
CascadeClassifier classfier;
//-- 1. Load the cascades
string cascade_name = "trained.xml";
if( !classfier.load( cascade_name ) )
{
cout << "--(!)Error loading face cascade\n";
return -1;
};
Mat frame;
... 이미지 읽기
//-- 2. Apply the classifier to the frame
detectAndDisplay(classfier,frame);
}
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
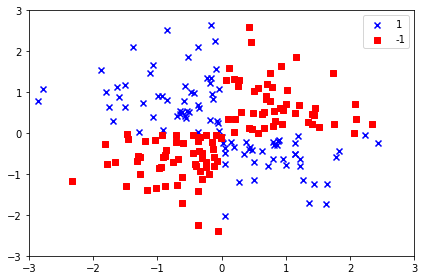
X = iris.data[:,[2,3]]
y = iris.target
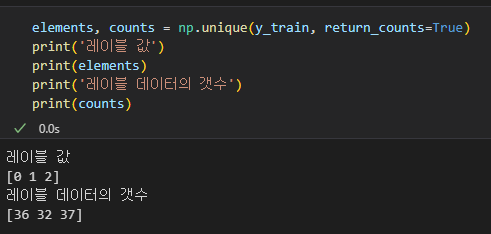
print('클래스 레이블 : ', np.unique(y))
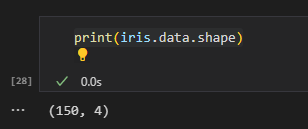
여기서 iris.data는 꽃의 샘플 데이터이다. iris.data의 구조는 아래와 같다.
보통 머신 러닝 프로젝트를 한다면 데이터를 분석하는게 제일 중요한 것 같다. (데이터를 분석한다는 것은 데이터의 차원, 분포도, 평균, 표준편차 등을 예시로 들 수 있다.)
iris.data[:,[2,3]]
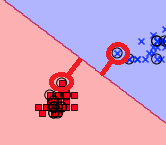
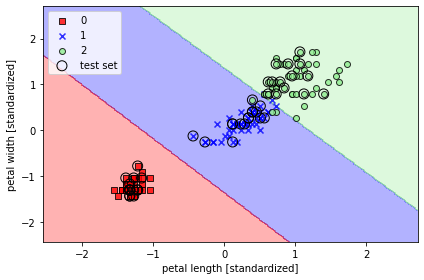
위와 같이 구성한 명령어는 꽃 분류 데이터의 2번째와 3번째 특성 데이터만 쓰겠다는 뜻이다. (추 후 Decision boundry로 그리기 위함 + 꽃을 분류하기에 충분히 의미 있는 데이터임)
from sklearn.model_selection import train_test_split
#X : 특성 데이터, y : 레이블 데이터, test_size : 데이터에서 테스트에 쓸 데이터 비율, random_state : random seed 값, stratify : 레이블 데이터의 비율 고정
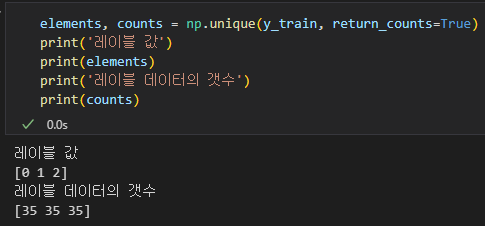
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
다음은 퍼셉트론 모델을 학습 하기 위한 데이터 분할이다.
테스트 셋은 0.3, 학습 데이터 셋은 0.7 비율이다.
그리고 stratify=y 파라미터 의미는 학습용, 테스트용 데이터 셋에 대해서 레이블 값을 균등하게 가지도록 하겠다는 뜻이다.
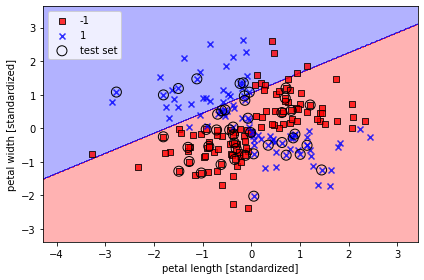
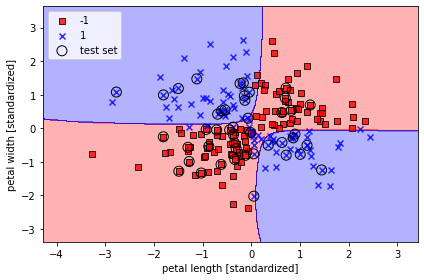
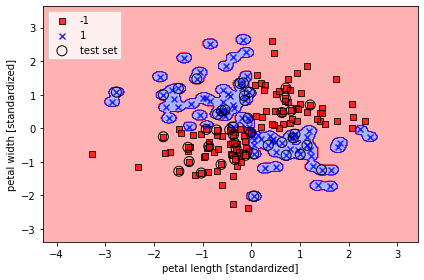
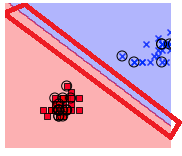
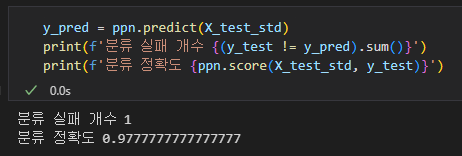
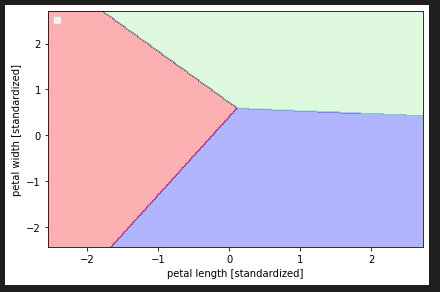
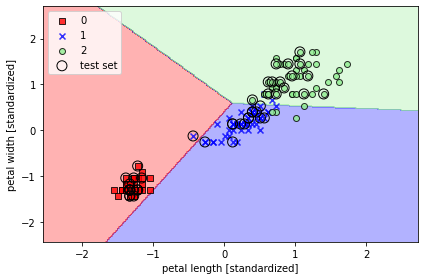
위의 에서 정의한 함수는 특성 데이터(x), 라벨 데이터(y), 모델 분류기(퍼셉트론 모델 등..) 을 받아서 Decision boundry를 그려주는 함수이다. 개인적으로 훈련한 모델이 특성 데이터(X)를 어떻게 보고 있는지 확인할 수 있는 그래프를 보는 것은 정말 재밌다.